
Learn Java8
Java8 学习笔记,PPT 备忘录~
Java 发展史
JDK 5

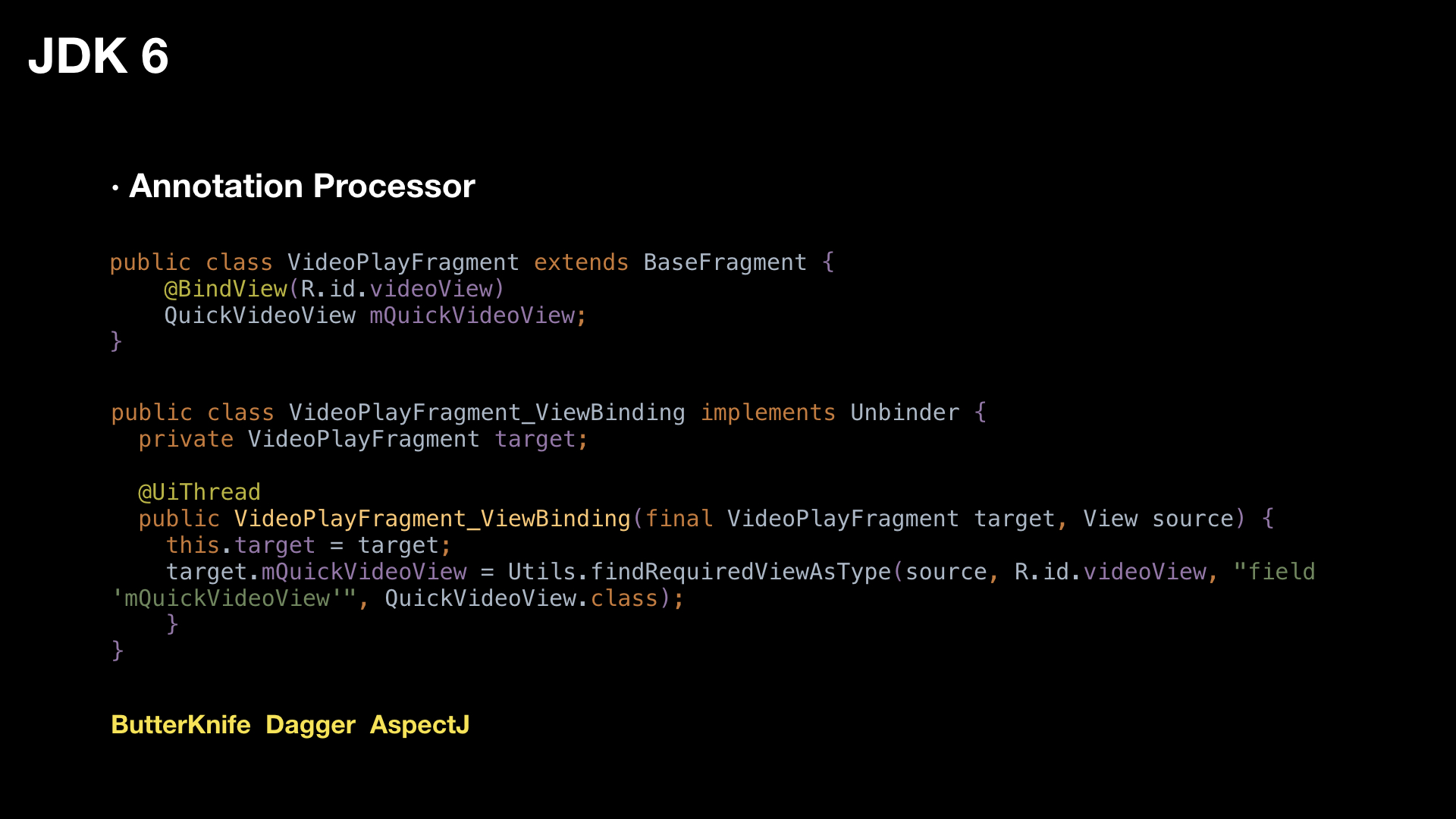
JDK 6
JDK 7

JDK 8

接口默认方法
默认方法让接口增加新方法的同时又能保证对使用这个接口的老版本代码的兼容
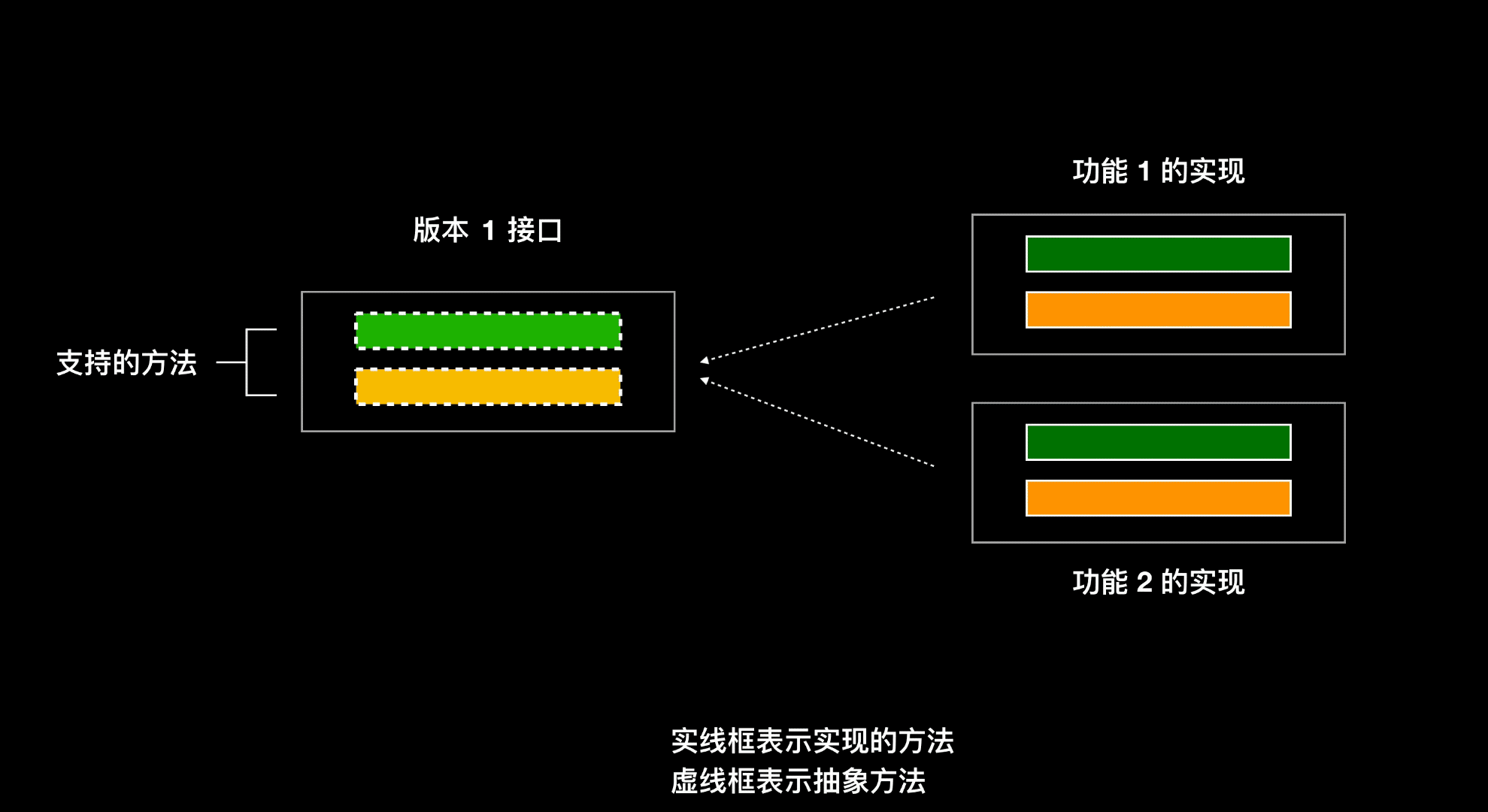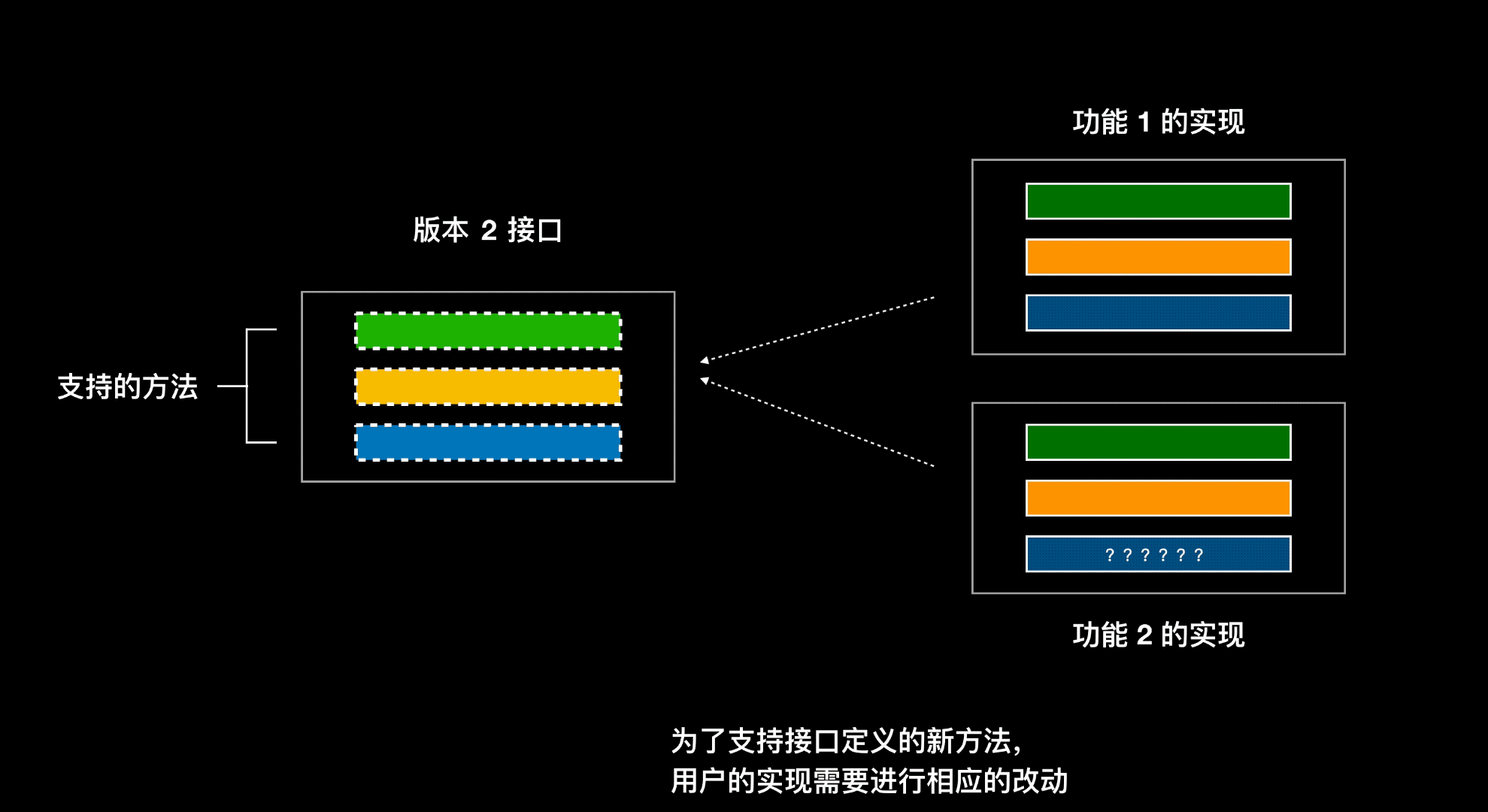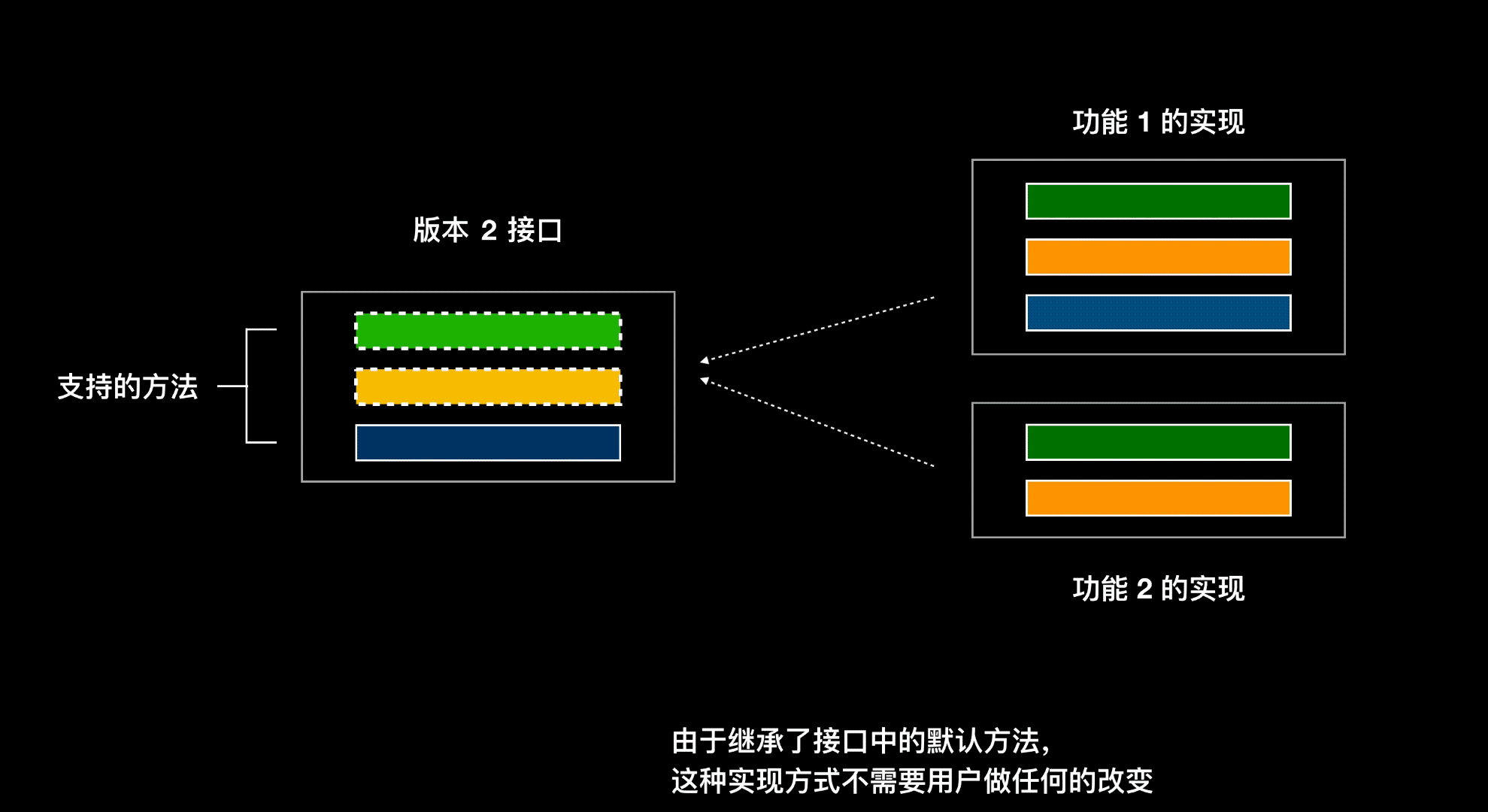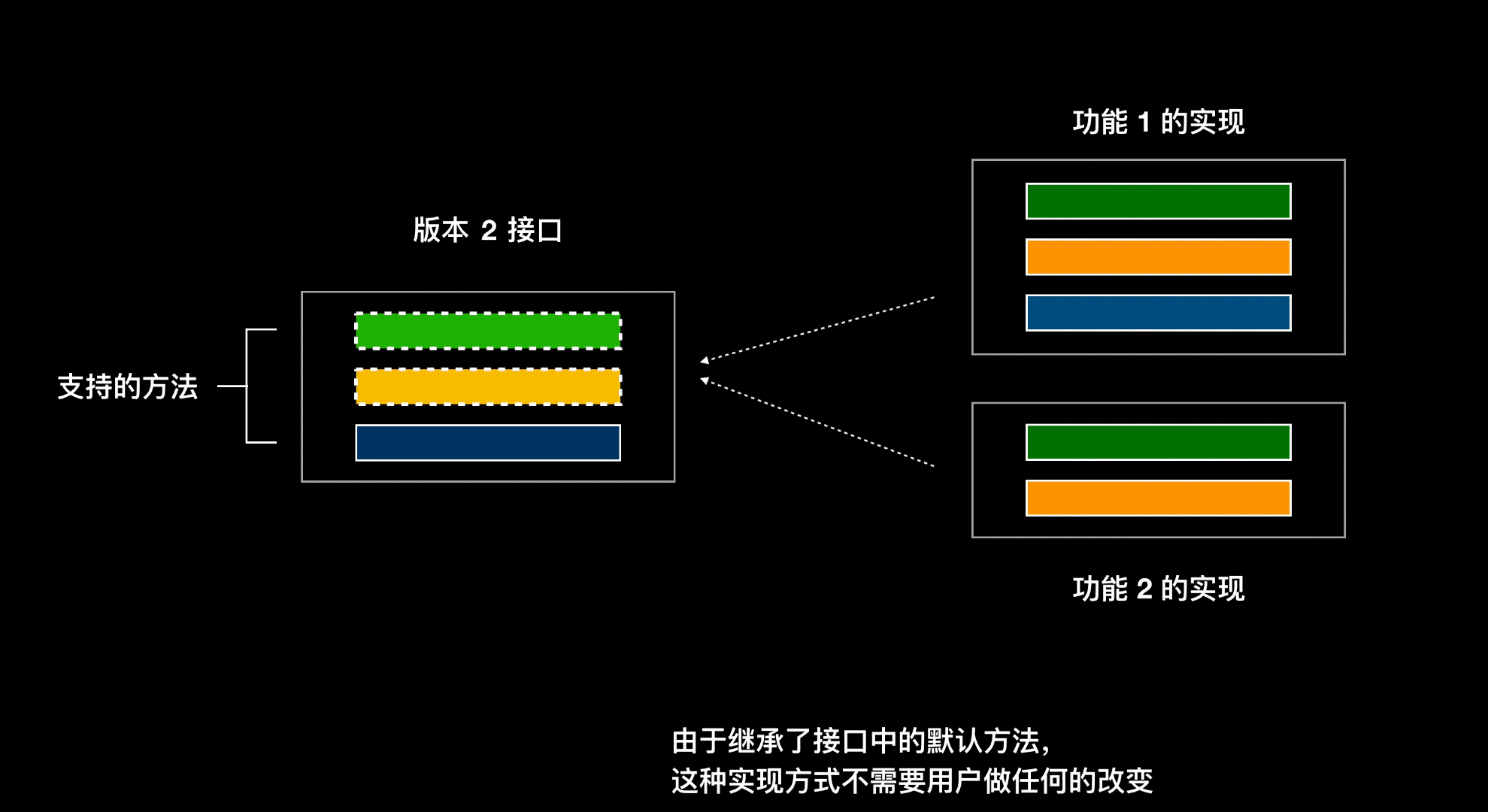
如果在面向接口编程里面,功能 1 要新增一个方法,在接口中添加了该方法,则实现该接口的其他类都得再去实现这个方法
- 如果改接口的实现类有很多,那么一个个类的去做实现很麻烦
- 该方法对某些类来说是没有意义的
- 如果这个接口是对外发布的,其他用户自己还去实现了该接口,当发布新版本的时候,其他用户会很蒙
所以在 Java8 中新增了接口默认方法,默认方法让接口增加新方法的同时又能保证对使用这个接口的老版本代码的兼容
二进制兼容

假设 gif 中的 Exoplayer、Exoplayer Wrapper 和 app 是分别三个团队,当 app 发现一个 bug 后一层层往上报,最终发现是 Exoplayer 团队的 bug,那么 Exoplayer 团队将 bug fix 了,发布了 Exoplayer 2.0 :
- 如果
Exoplayer 2.0不是二进行兼容的,那么Exoplayer Wrapper也需要重新编译发布 2.0 版本 - 如果
Exoplayer 2.0是二进行兼容的,那么Exoplayer Wrapper无需重新编译,app直接引用Exoplayer 2.0边行
『二进制兼容指在升级 (bug fix) 库文件的时候,不必重新编译使用这个库的可执行文件或使用这个库的其他库文件,程序的功能不被破坏』
接口的修改是二进制兼容的,但是如果这样修改了的话会让程序出现不可控的异常

用法
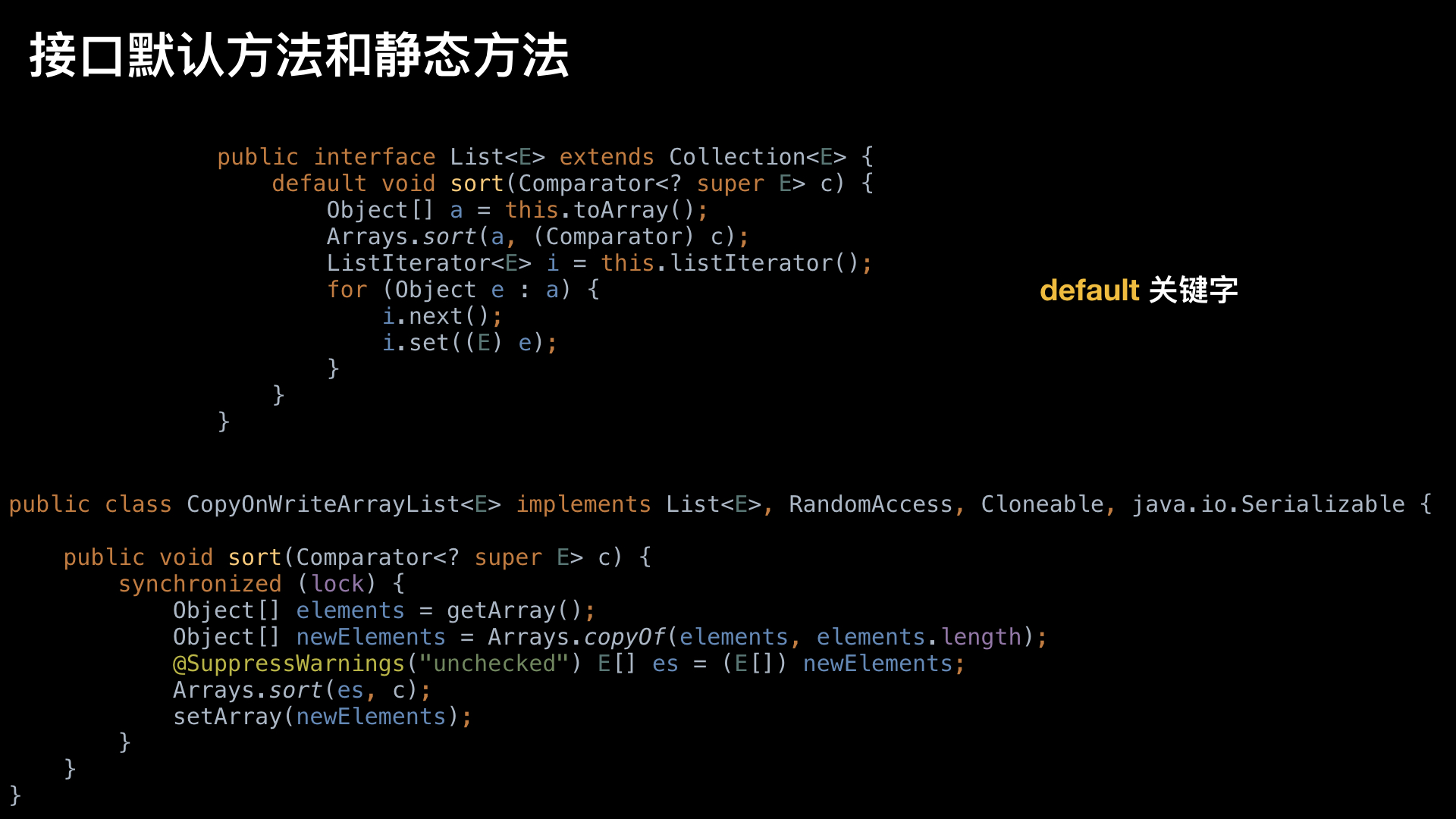
- 必须得有关键字
default修饰 - 实现类可以复写接口的默认方法
冲突
一个类只能继承一个父类,可以实现多个接口
但是加了默认方法之后,在默认方法的使用上出现了一些冲突

- 类中的方法优先级最高:
- 类或父类中声明的方法的优先级高于任何声明为默认方法的优先级
- 如果父类中的该方法是抽象的,子类如果不是抽象类则必须实现该方法
- 子接口优先级更高
- 如果实现两个接口中的默认方法相同,需要显示解决冲突:Error: class B inherits unrelated defaults for hello() from types A and C
小结
- 开头以关键字
default修饰,方法体与常规的类相同 - 帮助库设计者以向后兼容的方式演进 API
- 可以用于创建可选方法和行为的多继承
- 能够解决多继承的冲突
Optional
Optional 是 Java 8 提供的为了解决 null 安全问题的一个 API
- NullPointerException 是程序中最典型的异常
- 让代码充斥着深度嵌套 null 检查 / 代码可读性差
- null 某种程度上来说是没有任何意义的
1 | def path = mManagerData?.getData()?.getInfo()?.getPath() : getDefaultPath(); |
Java 8 为啥不引入安全操作符 呢?先来看看 Optional :
1 | public String getPath() { |
整个样式结构跟 Stream 很相似,当然搭配着 Stream 食用味道更佳
1 | public Optional<ManagerData> getFirstDraftData() { |
如果是对外提供功能,返回值是一个 Optional 的话更能让调用者知道该怎么操作
1 | public String getPath() { |
orElse 方法的延时调用版 orElesGet :如果是 orElse 默认情况下会先去初始化失败情况下的值,如果是 orElesGet 的话,只有失败了的情况才会走其中的方法
小结
- 对缺失的变量值进行建模
- 提供了丰富的 API,与 Stream 十分相似
- 更好的设计 API ,调用方只需要看一下返回类型就知道该怎么操作
Lambda
用更简洁流畅的代码完成一个功能
举栗
版本 1
1 | public static List<Apple> filterGreenApples(List<Apple> list) { |
第一个版本,需要将绿颜色的苹果给挑选出来
版本 2
1 | public static List<Apple> filterColorApples(List<Apple> list, String color) { |
经过第一个版本后,需求改了,颜色可能是各种各样的,那么将颜色作为参数传进来的方式来满足需求
####版本 3
1 | public static List<Apple> filterColorOrWeightApples(List<Apple> list, String color, int weight) { |
又经过一个版本,判断条件可能不止颜色,还有重量,那么再将重量作为参数传进来;但是这样的做法会显得越来越笨拙
版本 4
1 | public static List<Apple> filter(List<Apple> list, Filter filter) { |
那么优化一下,通过类似策略模式的方式,放入不同的算法来实现
1 | class WeightFilter implements Filter { |
这样就把行为抽象出来了,代码适应了需求的变化,但是这个过程很啰嗦,因为需要声明很多只需要实例化一次的类
版本 5
1 | list = filter(list, new Filter() { |
再优化一下上个版本的问题,改为用匿名内部类,虽然上个版本的问题解决了,但是匿名内部类看起来很笨重,占用空间多,除此之外,有时候看起来还特别费力
1 | int weight = 100; |
此时的 weight 看起来就比较费力,到底引用的是外部的还是内部的呢
版本 6
1 | list = filter(list, apple -> apple.weight > 100); |
通过 lambda 的方式,再来解决匿名内部类带来的问题
Lambda 结构


函数式接口
只定义了一个抽象方法的接口
1 | @FunctionalInterface |
如果再往 Runnable 中加方法,会导致编译失败
占用字节码更少

小结
- 更简洁的传递代码
- 函数式接口就是只有一个抽象方法的接口
- 只有在函数式接口的地方才能使用 Lambda
- 方法引用可以复用现有的方法实现并直接传递
Stream
Stream 可以更好的、更为流畅的、更为语义化的操作集合
Stream 作为 Java 8 的一大亮点,它与 java.io 包里的 InputStream 和 OutputStream 是完全不同的概念。Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。所以说,Java 8 中首次出现的 java.util.stream 是一个函数式语言 + 多核时代综合影响的产物。

流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
数据操作又可以分为无状态的 (Stateless) 和有状态的 (Stateful) ,无状态中间操作是指元素的处理不受前面元素的影响,而有状态的中间操作必须等到所有元素处理之后才知道最终结果,比如排序是有状态操作,在读取所有元素之前并不能确定排序结果
终端操作又可以分为短路操作和非短路操作,短路操作是指不用处理全部元素就可以返回结果,比如找到第一个满足条件的元素
Stream 举栗
结构图,栗子中要用到
1 | class Dish { |
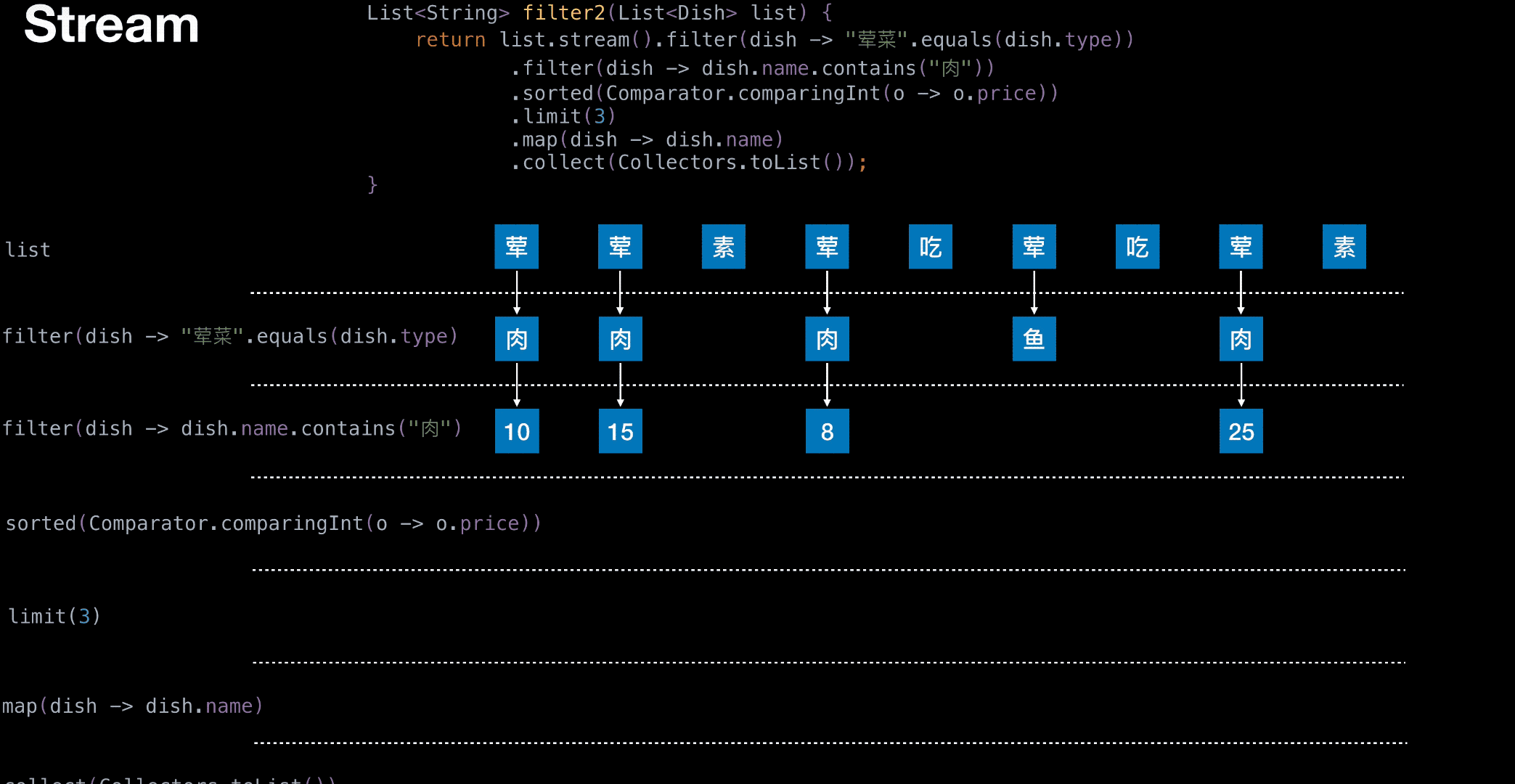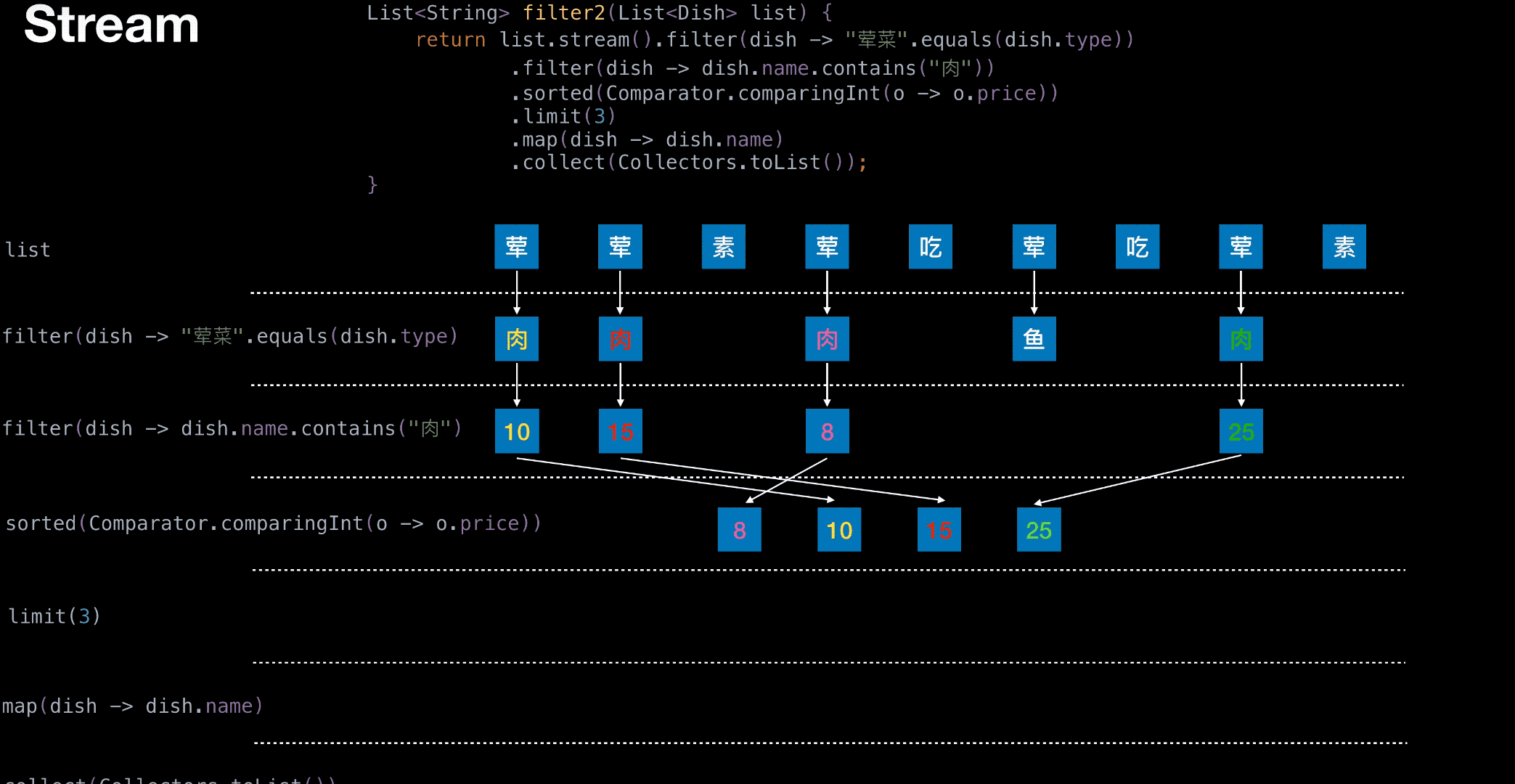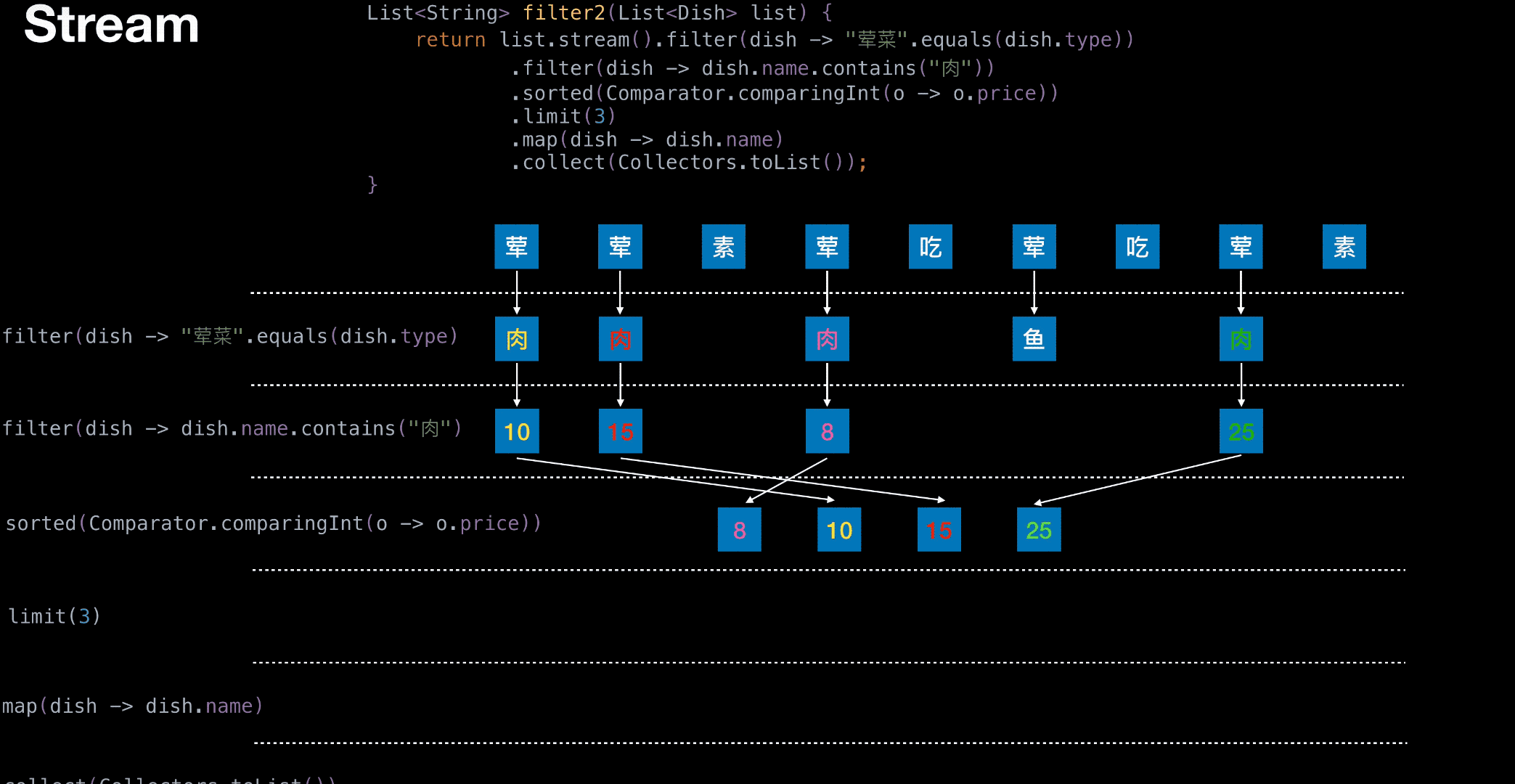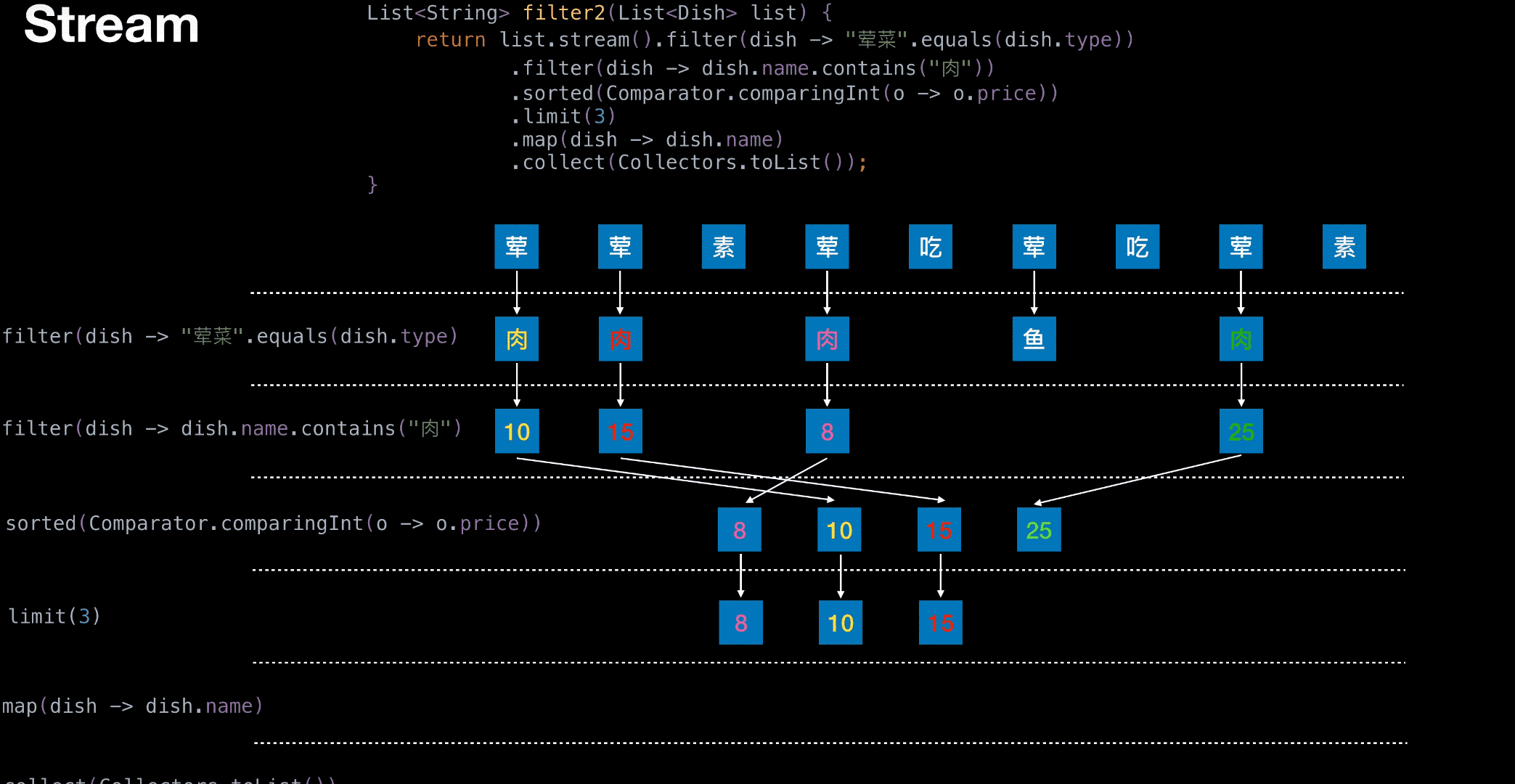
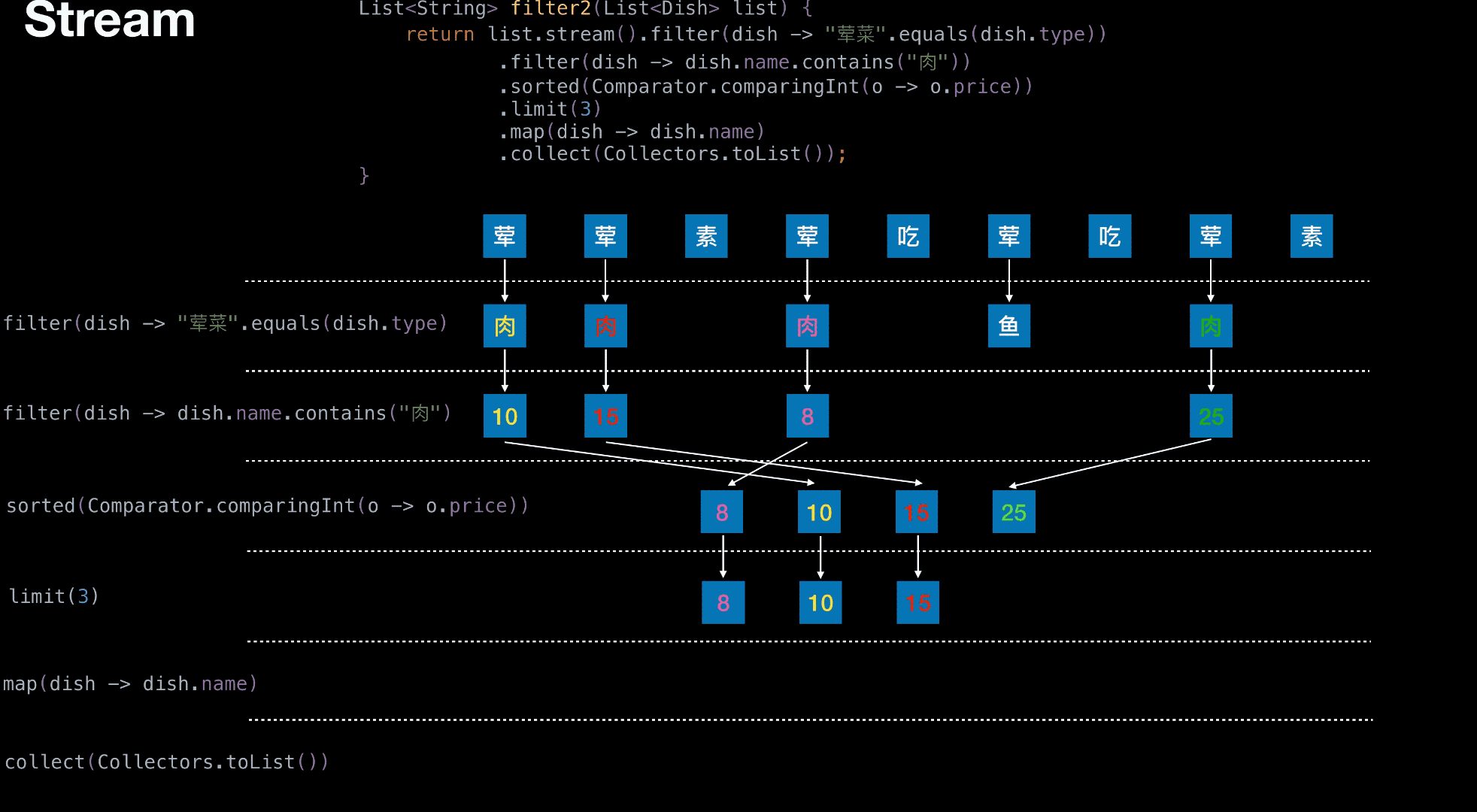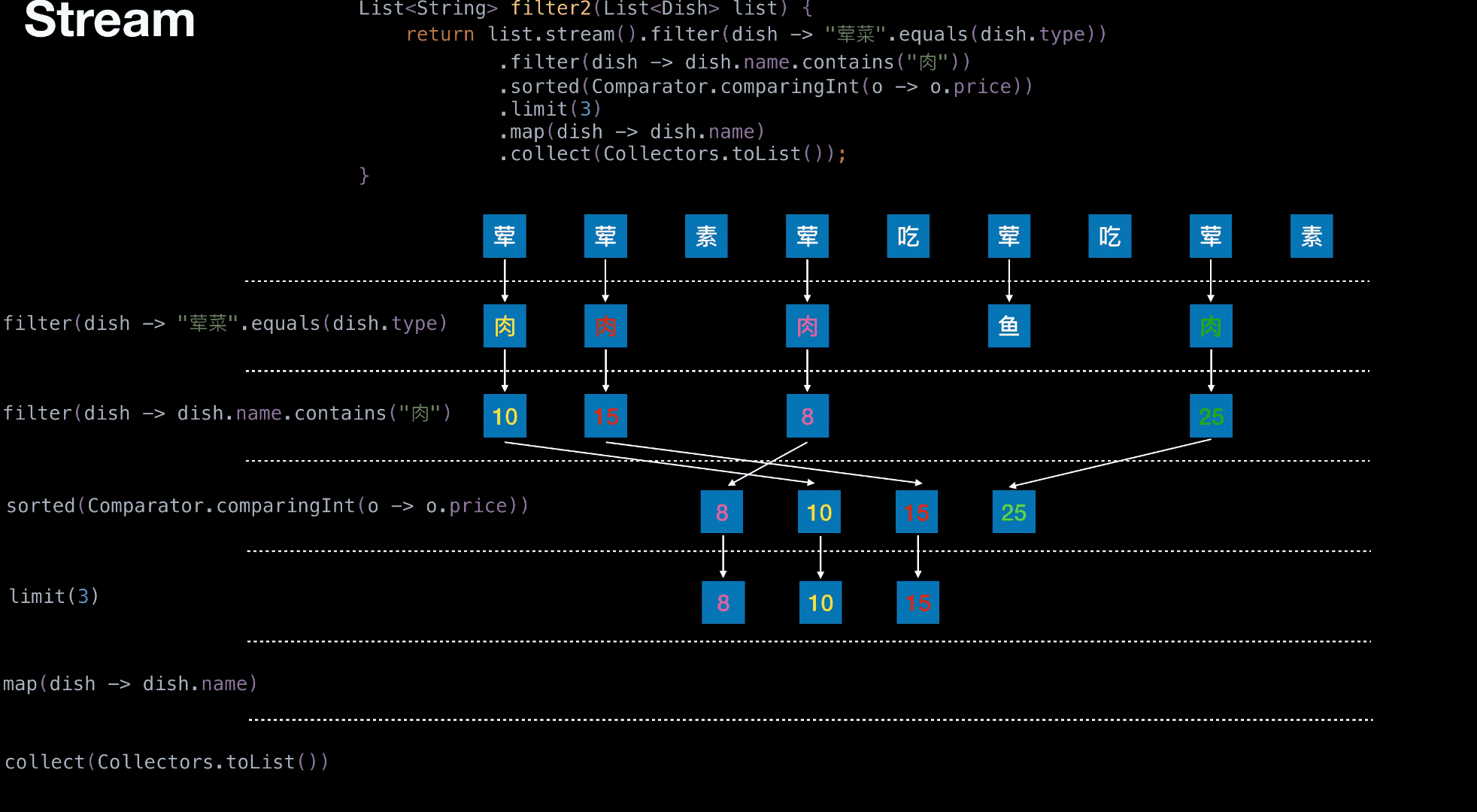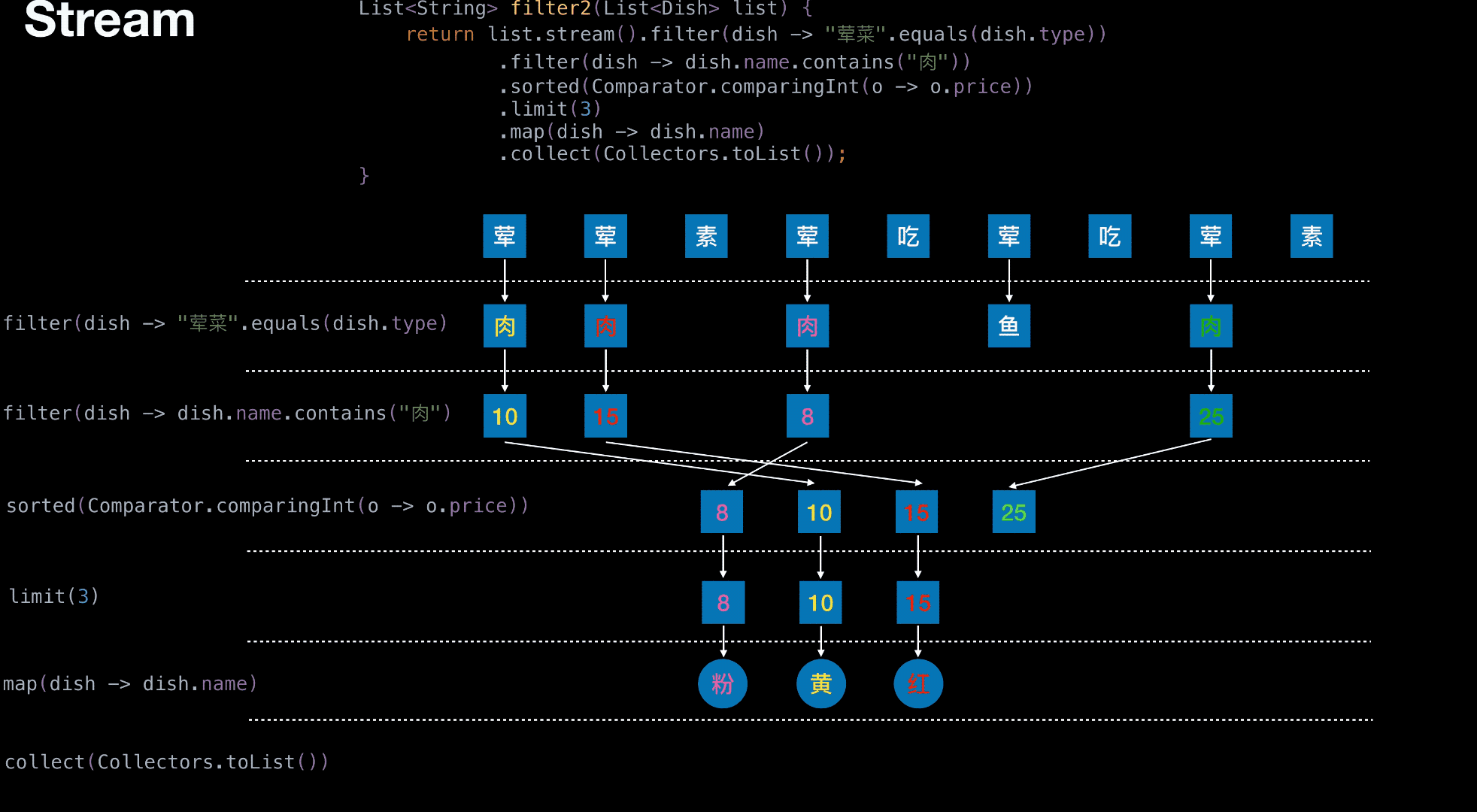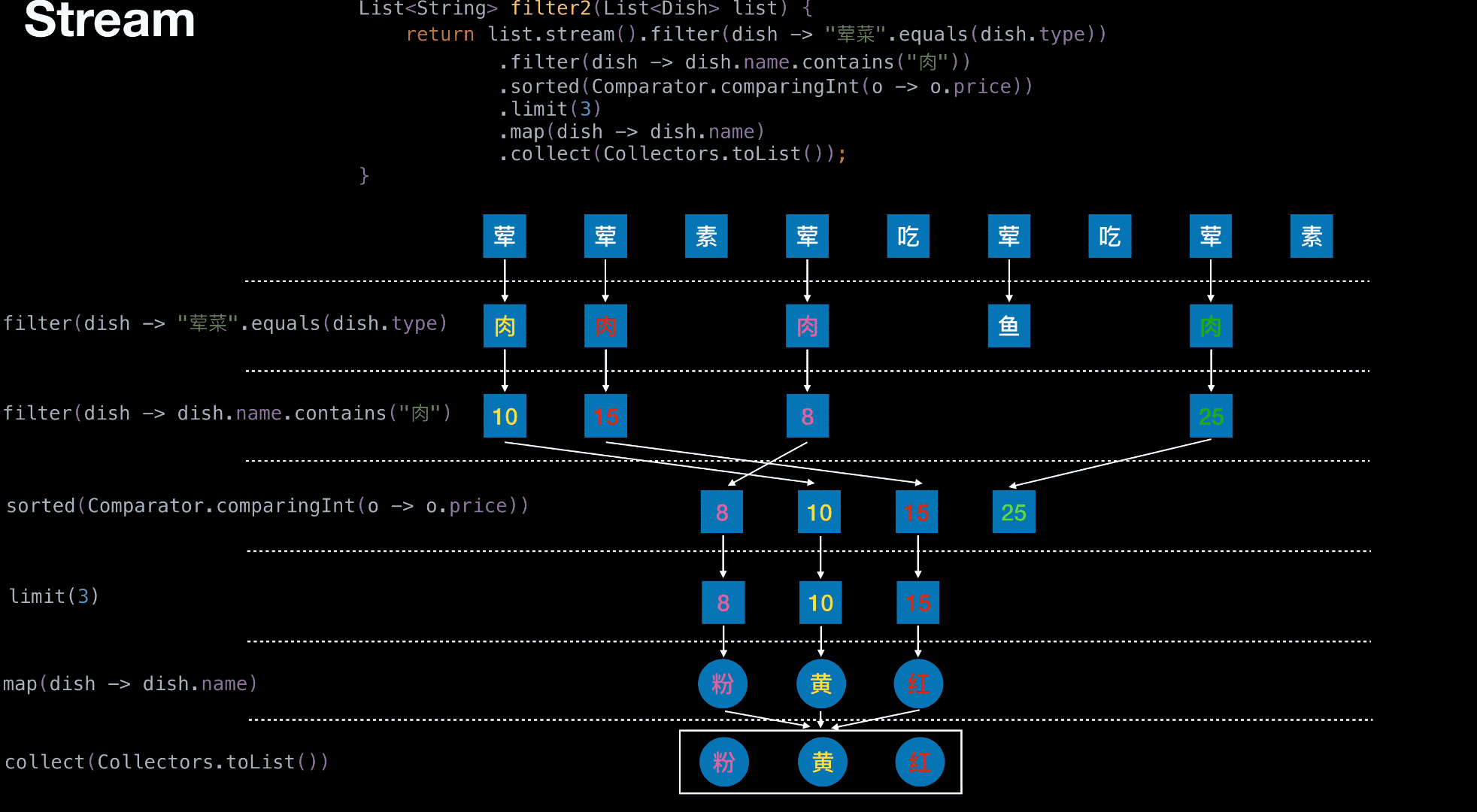
从菜单中挑选出 荤菜 且 菜名带『肉』字 且 价格最贵的 3 个
申明式
1 | List<String> filter(List<Dish> list) { |
Stream
1 | List<String> filter2(List<Dish> list) { |
有无状态举栗
无状态
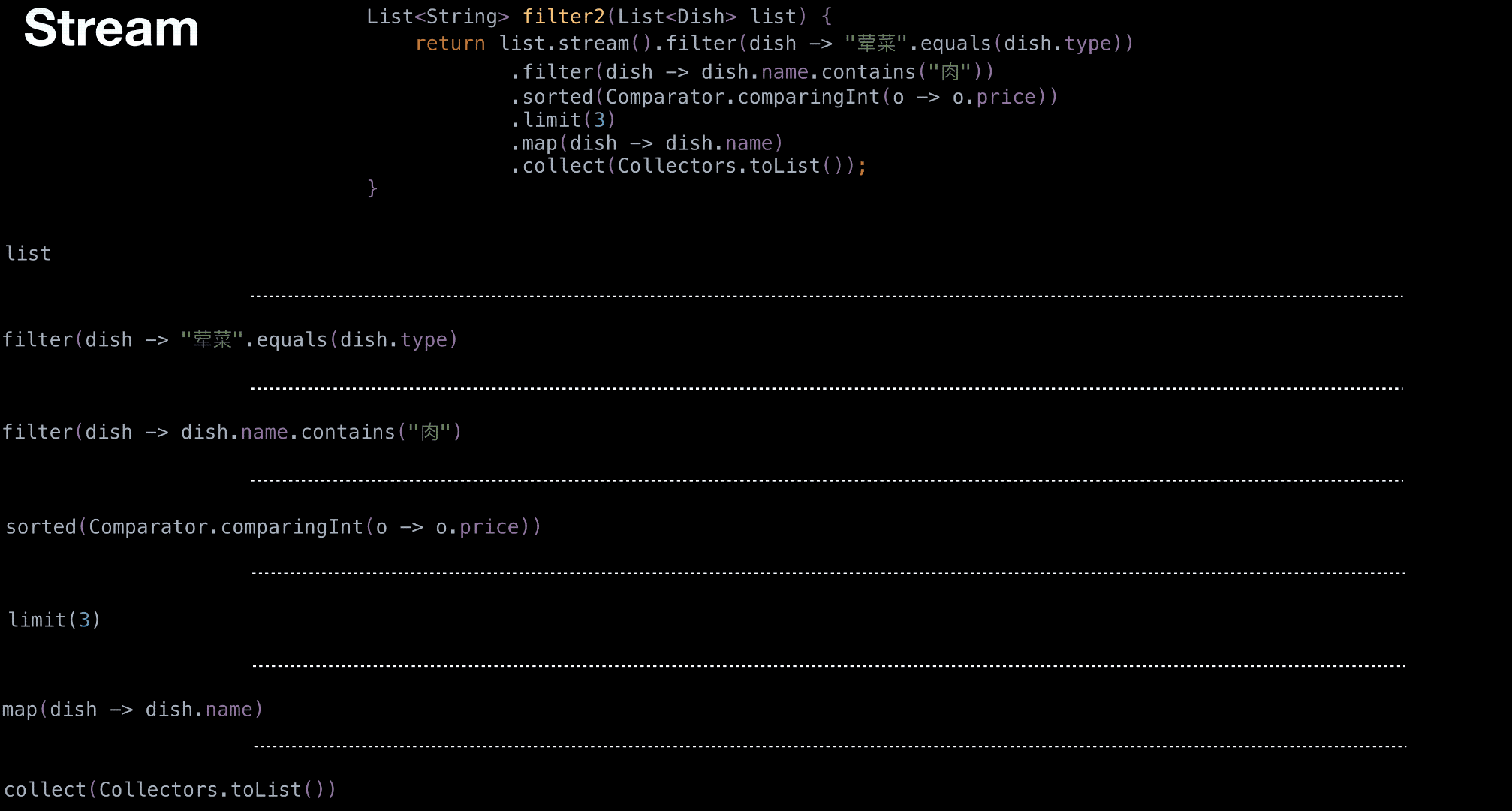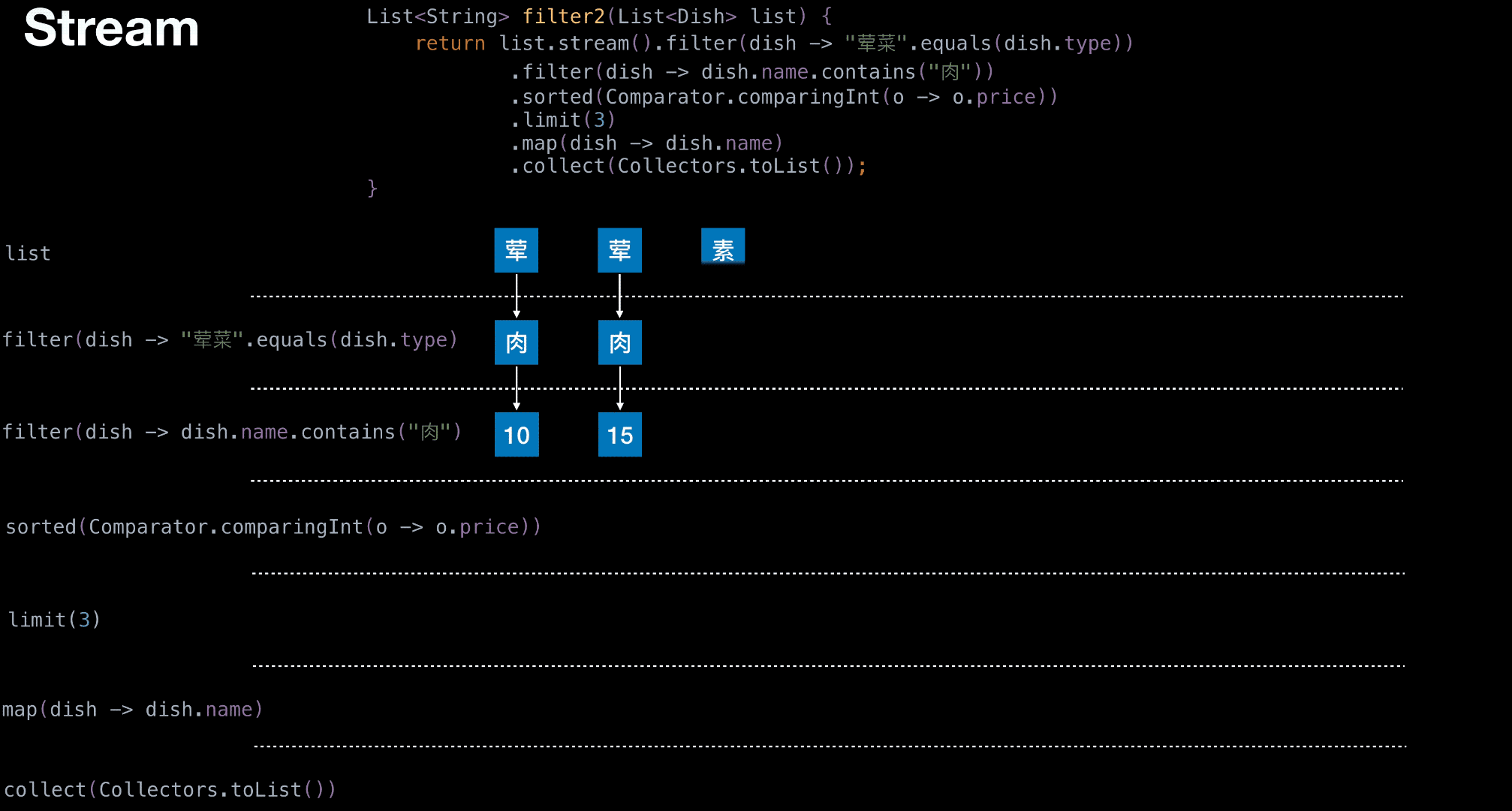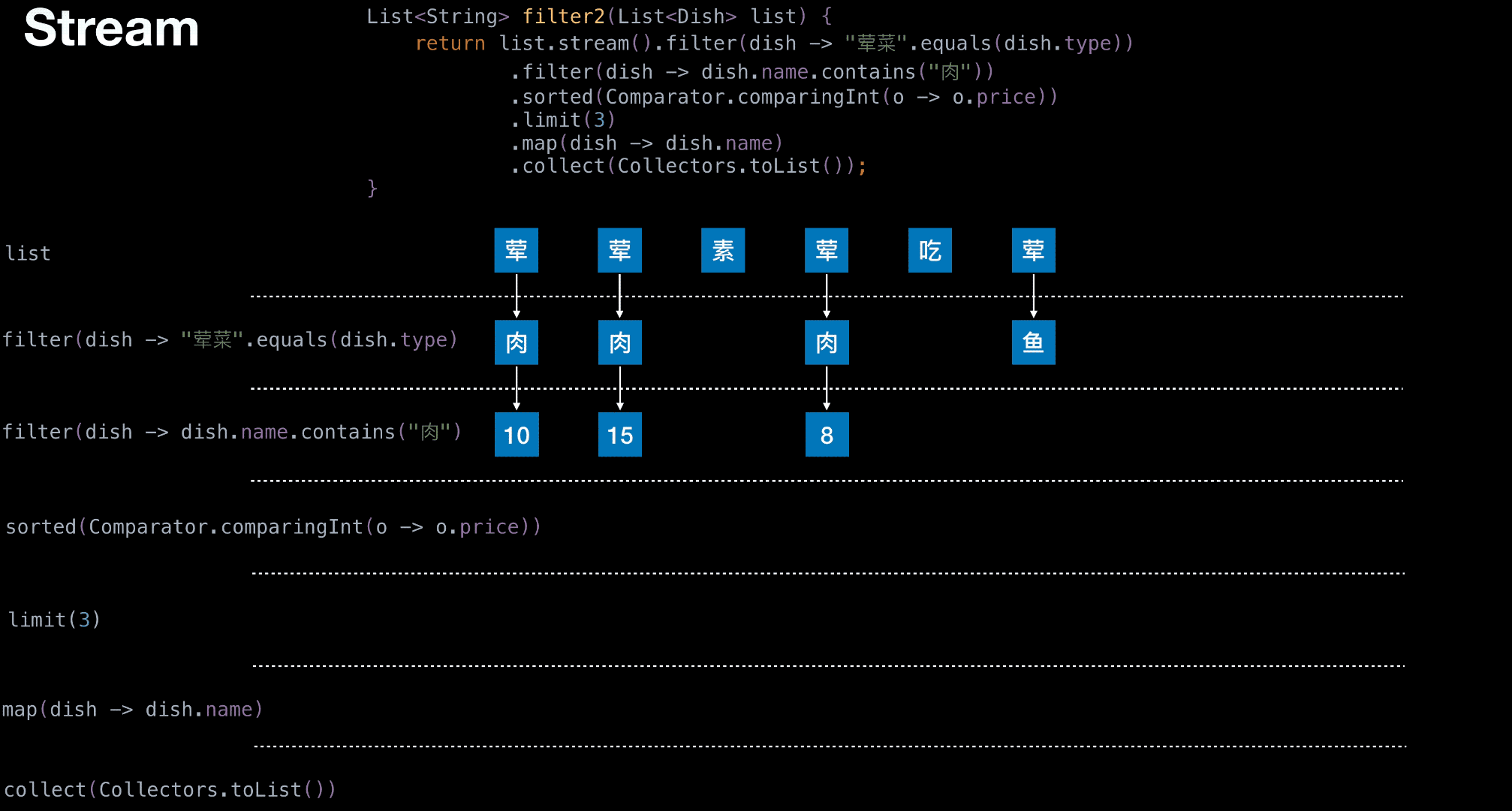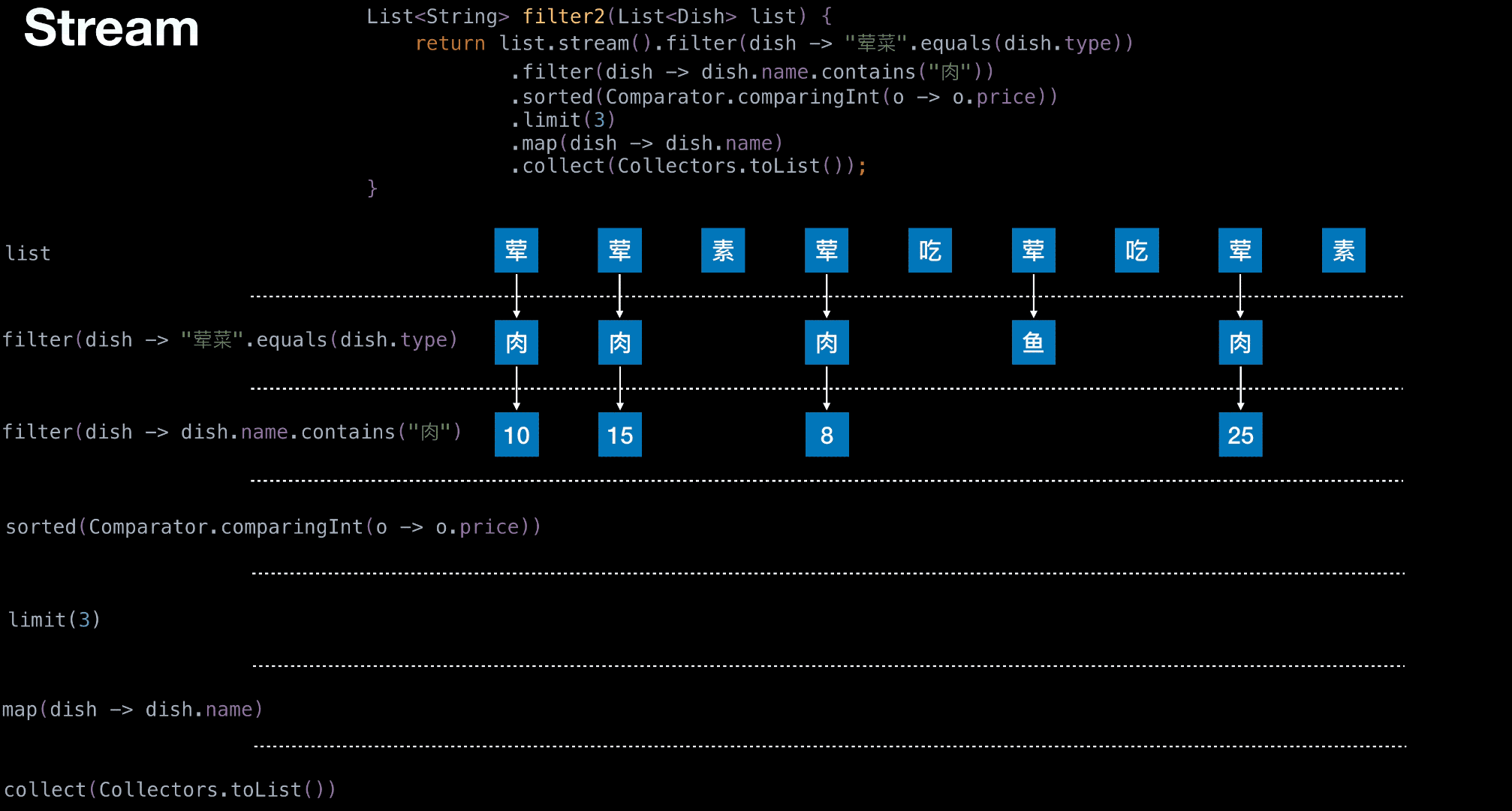
有状态
短路非短路举栗
非短路
短路

内部迭代
1 | List<String> filter2(List<Dish> list) { |
像 SQL,像 builder 构建者模式
流水线(管道)
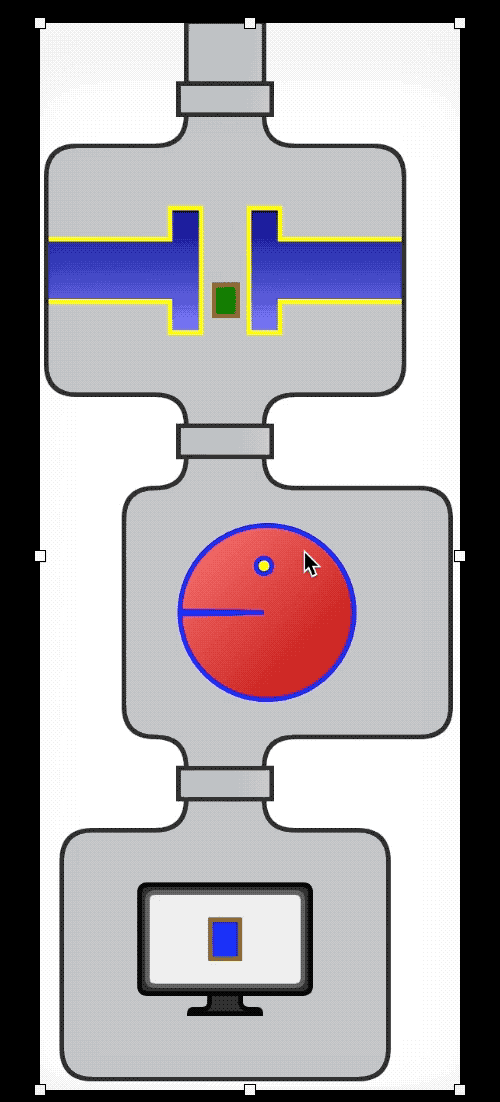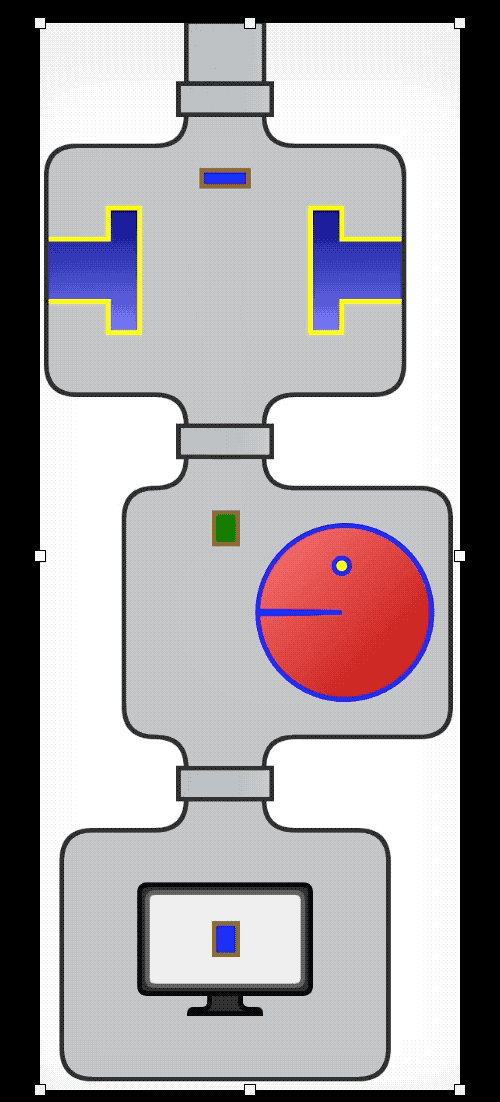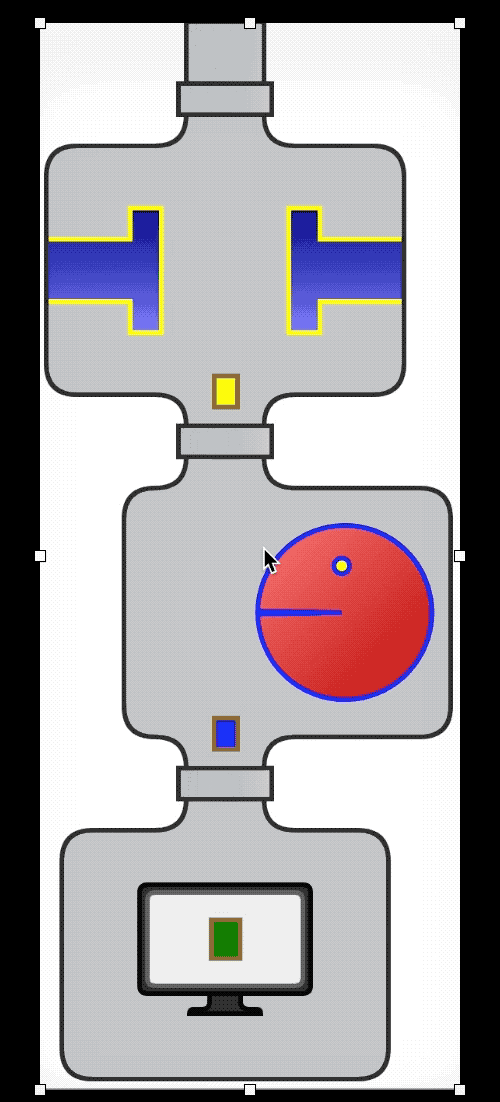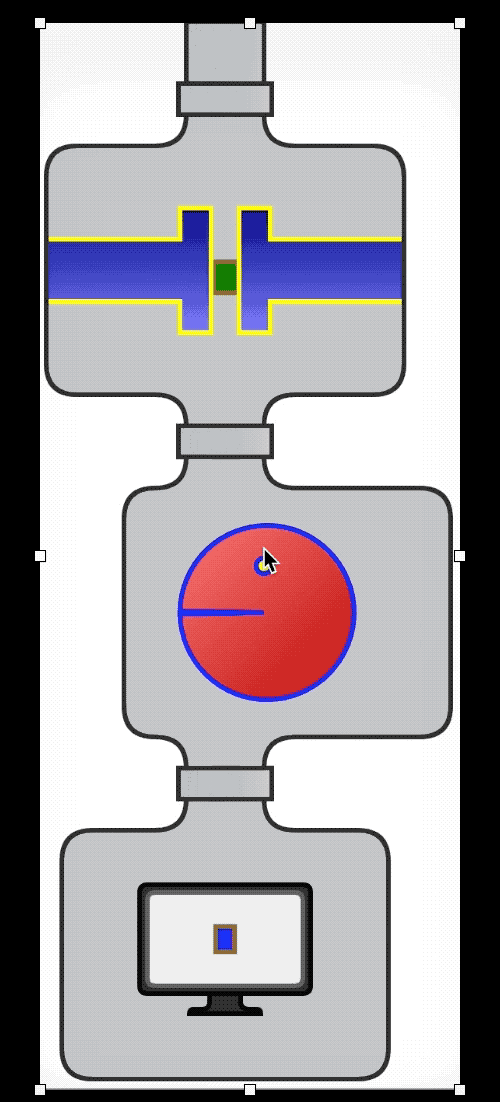
集合是一种数据结构;它的主要关注点是在内存中组织数据,而且集合会在一段时间内持久存在。集合通常可用作流管道的来源或目标,但流的关注点是计算,而不是数据;每个中间操作都返回流,让整个流能串起来
自动并行
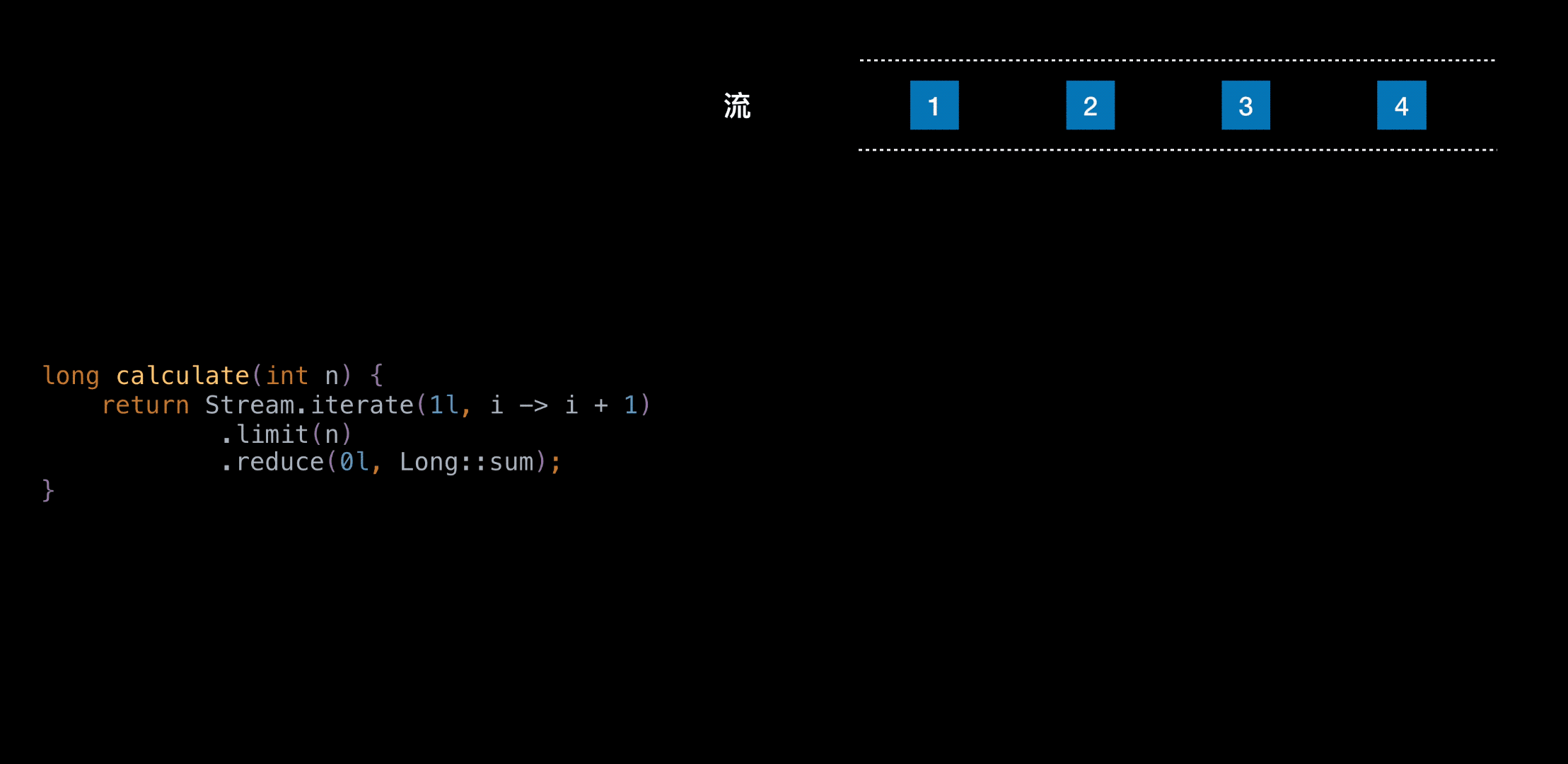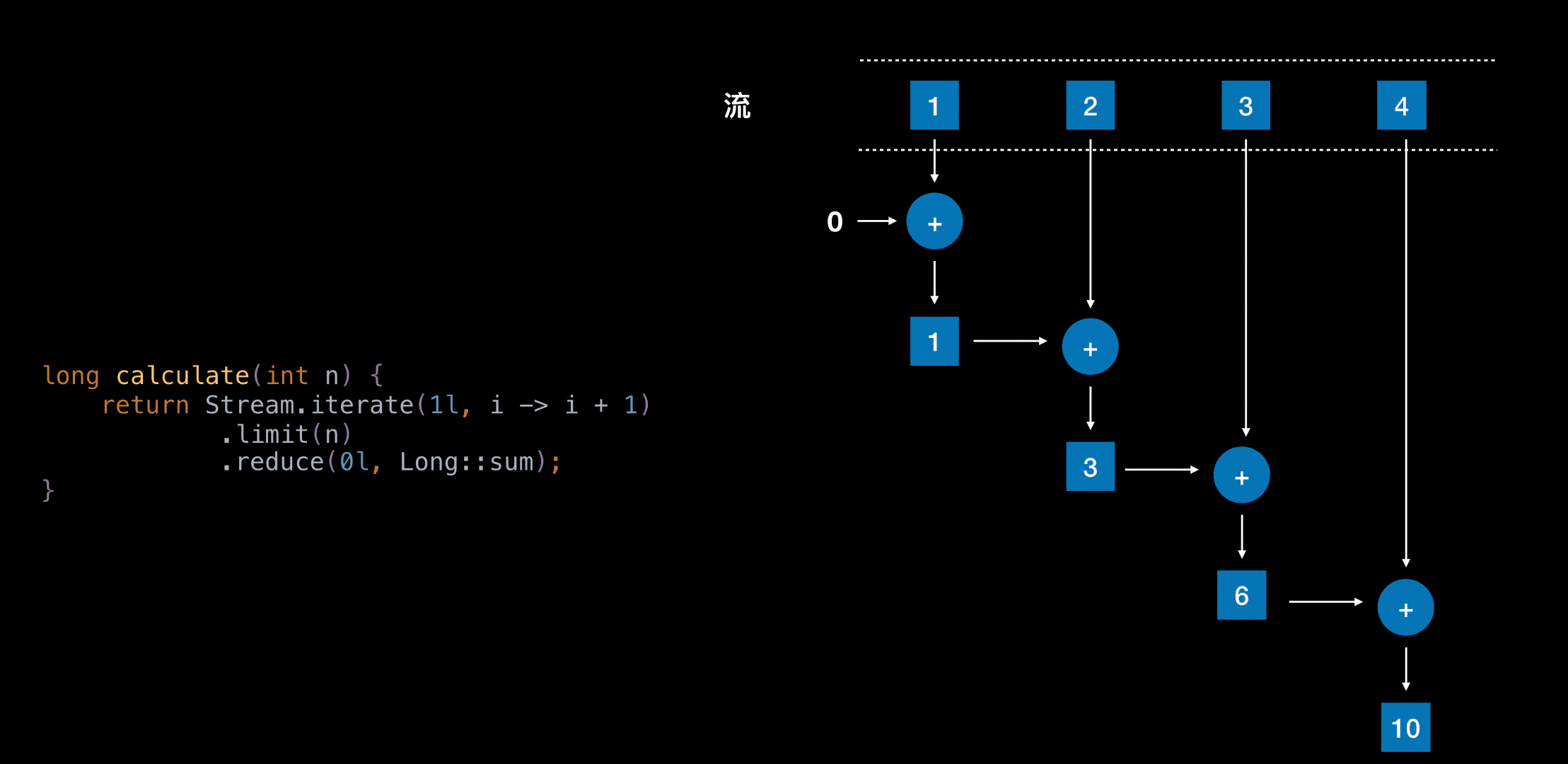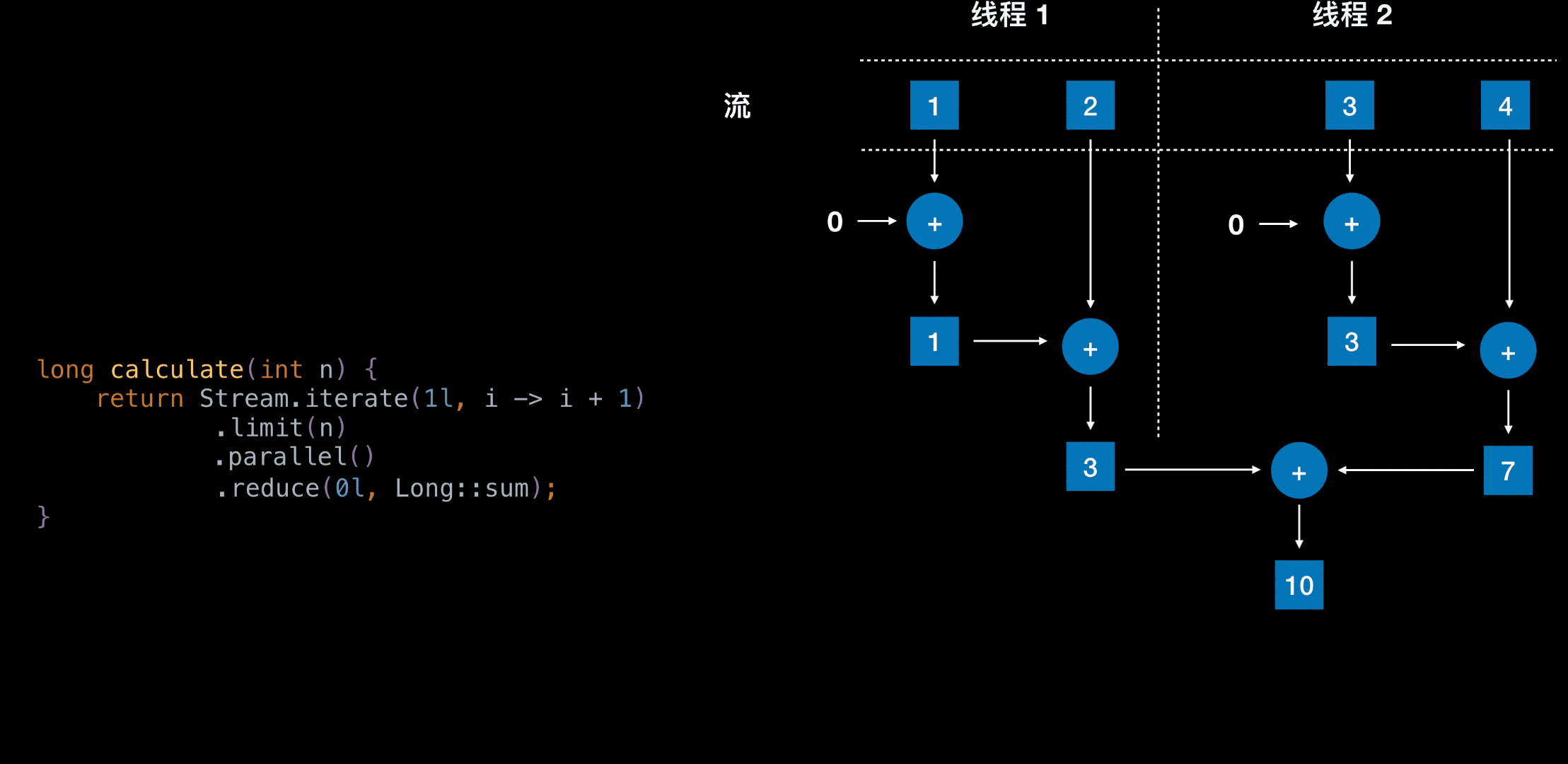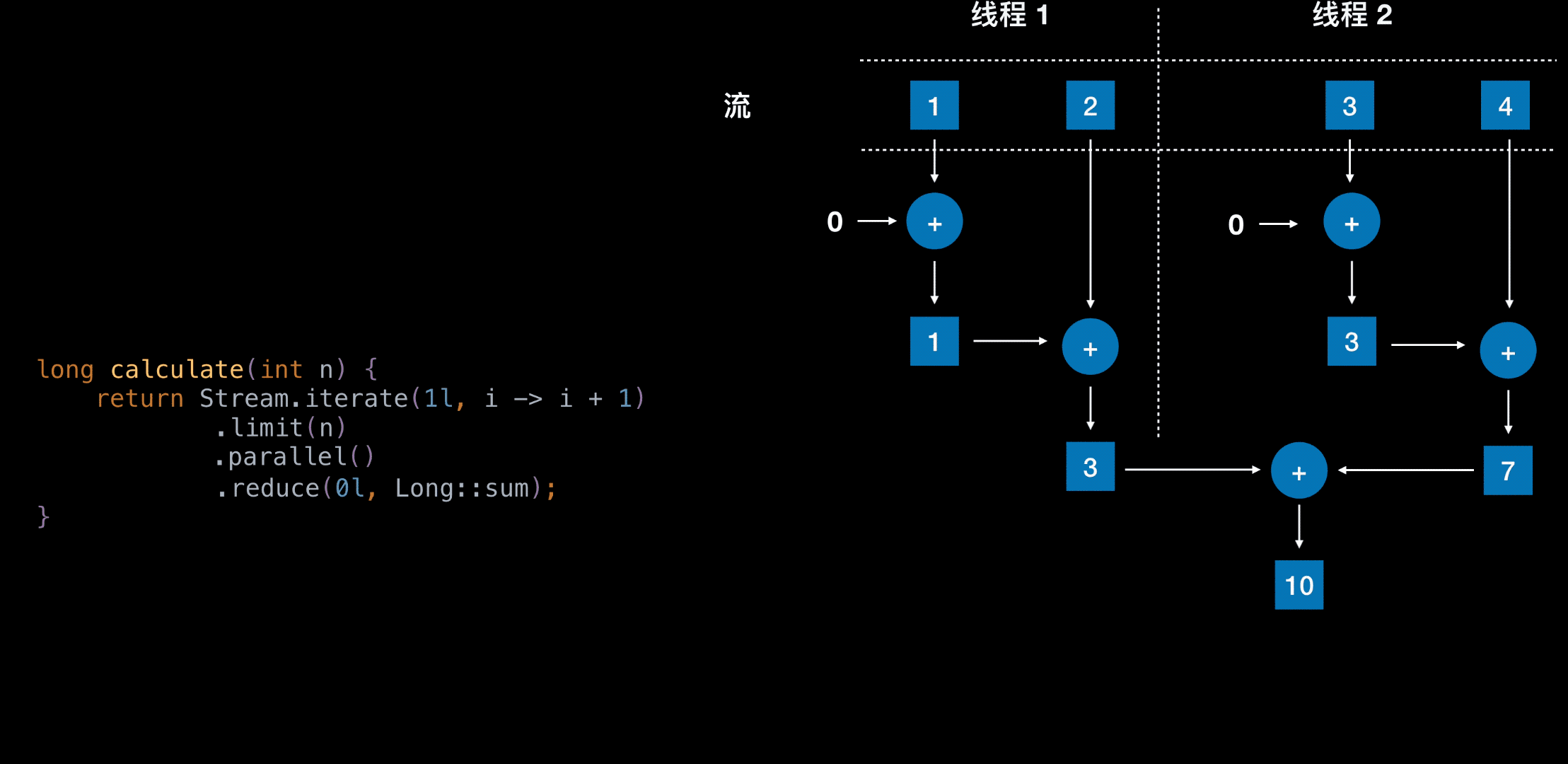
自动并行是采用的 Fork / Join 框架
分而治之
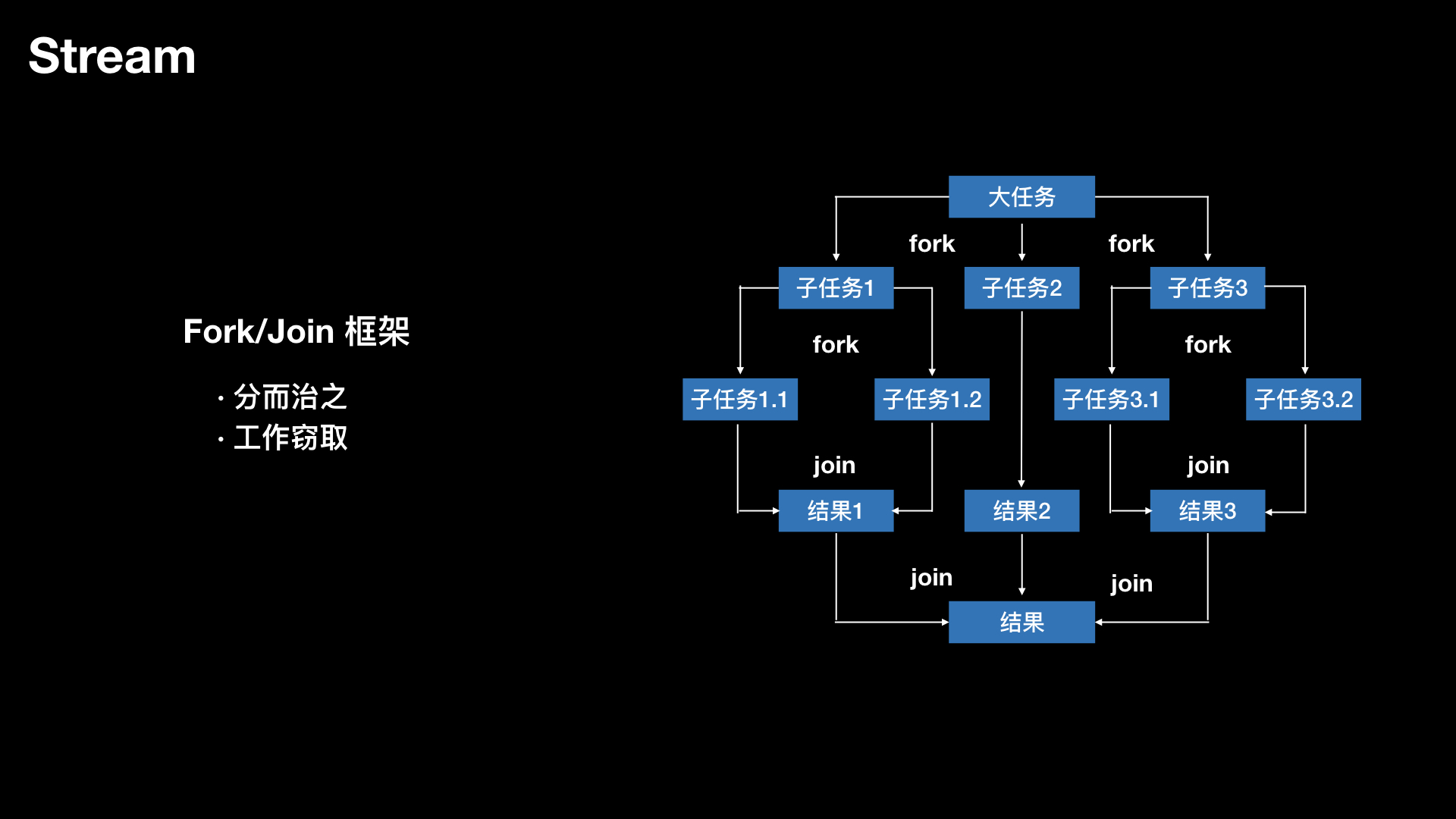
把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果
工作窃取
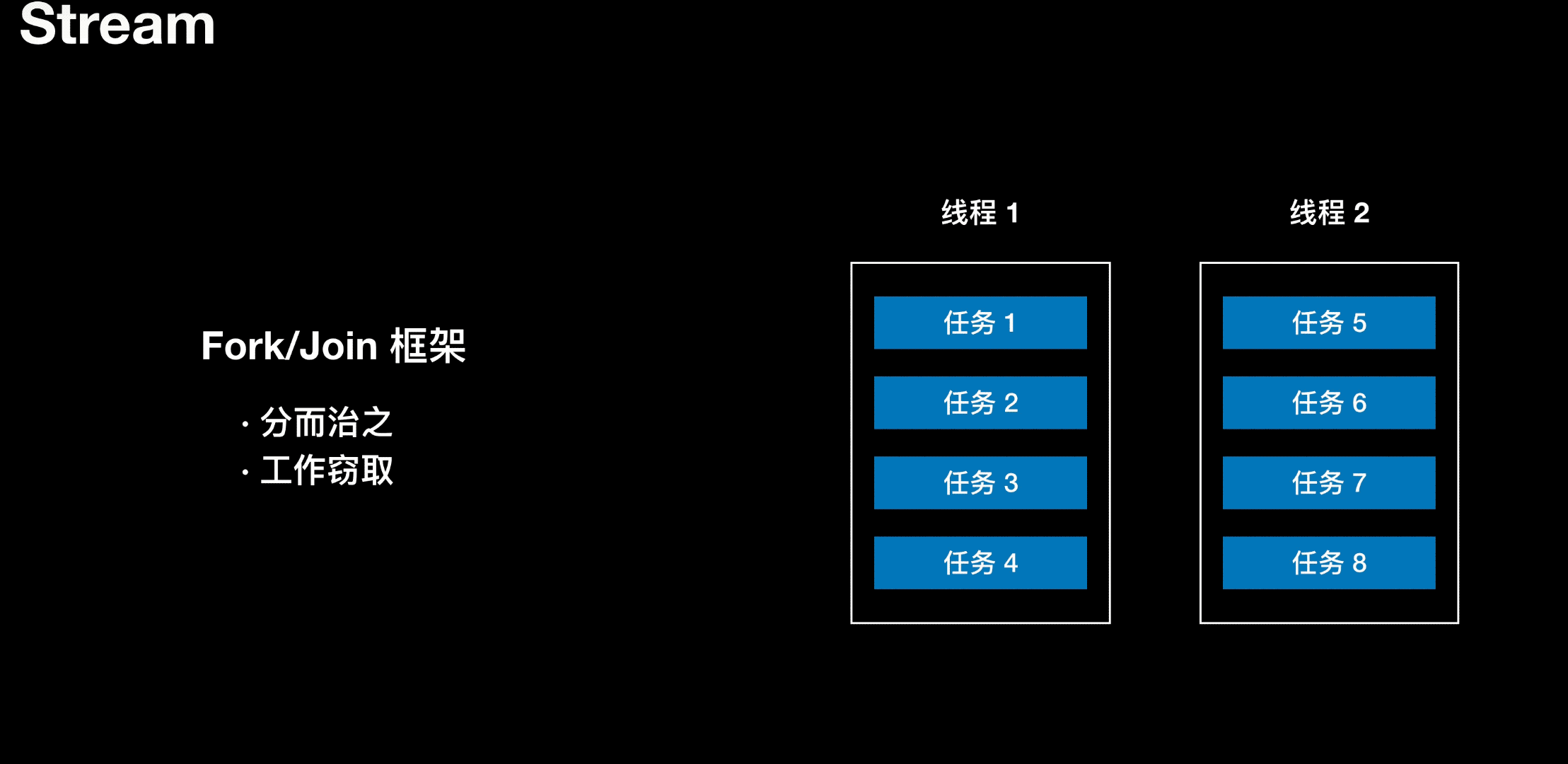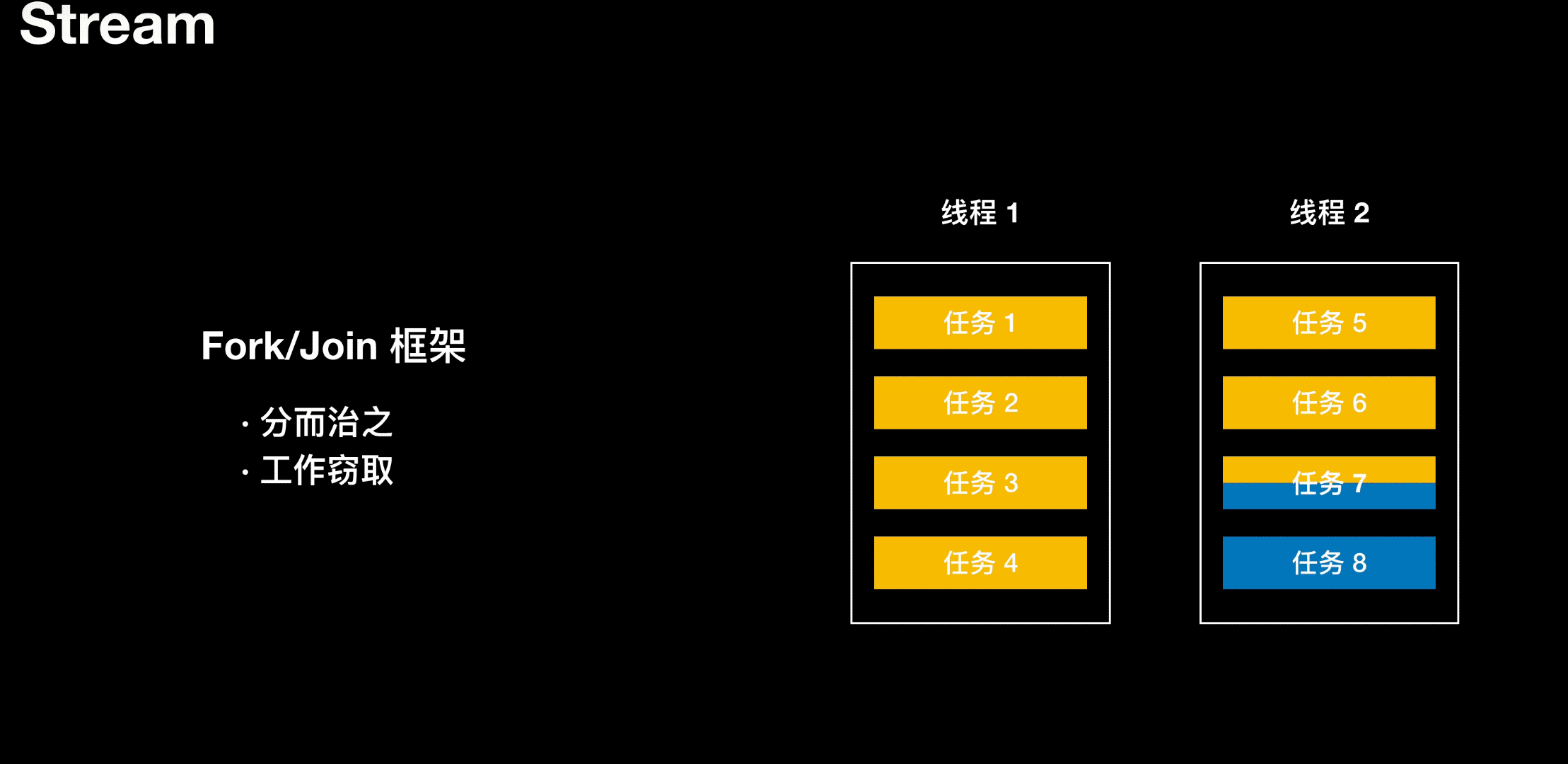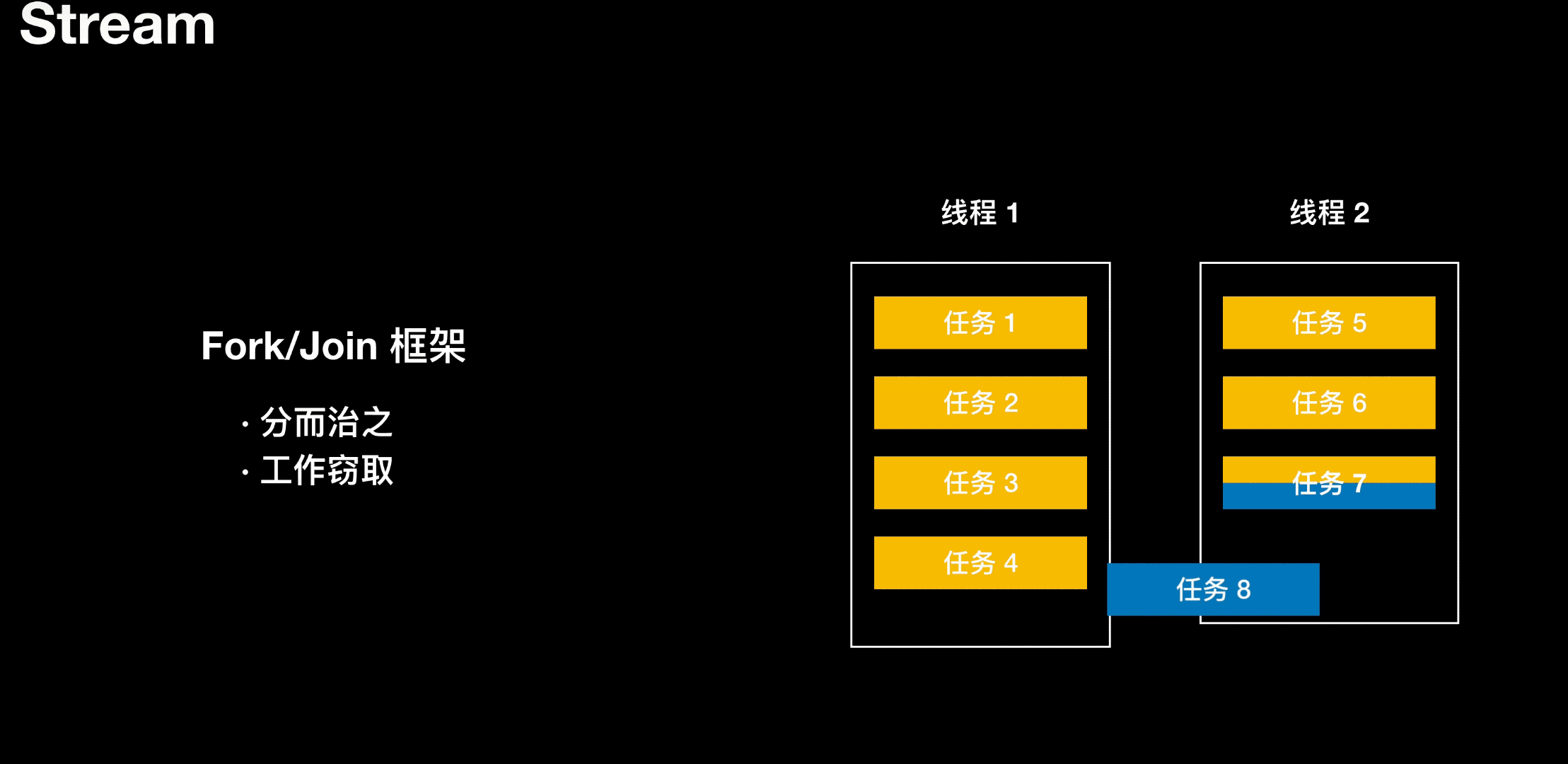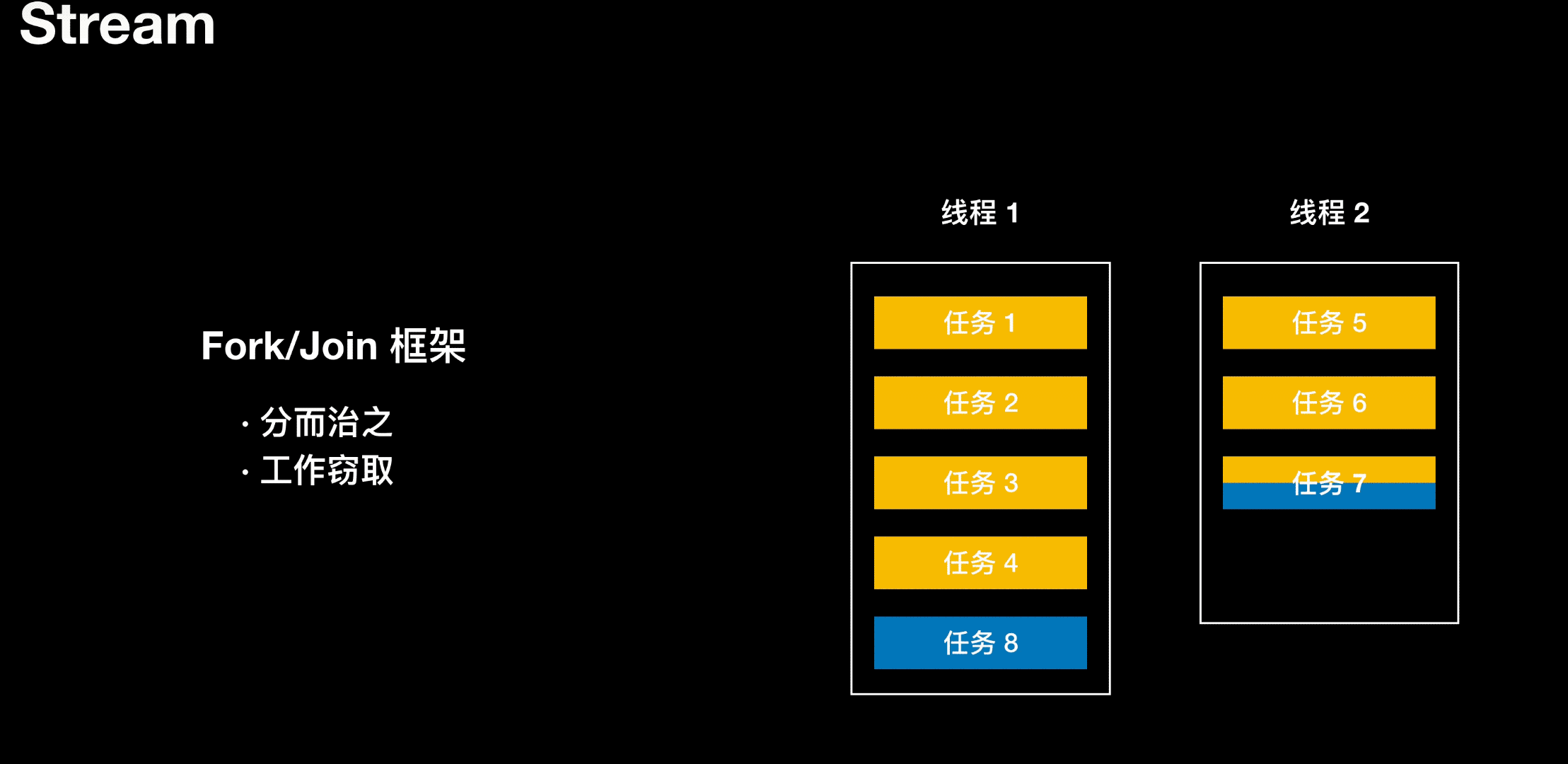
线程 1 负责处理 4 个任务,线程 2 负责处理 4 个任务,当线程 1 任务处理完了,但线程 2 还在处理任务。干完活的线程与其闲着,不如去帮其他线程干活。于是它就去其他线程的队里里窃取一个任务来执行。在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务之间的竞争,通过会使用双端队列,被窃取任务线程永远从双端队列的头部执行任务,而窃取任务线程用于从双端队列的尾部拿任务。
小结
- Stream API 能够表达打杂的数据处理查询
- 对于装箱拆箱提供了对应 API
- 内部迭代可以透明的实现并行流处理
- 并不是任何情况都适合并行处理